sedna-ji-fl-controller-optimization-v1-en
KubeEdge-Sedna
Repo: https://github.com/kubeedge/sedna
Related PRs:
- initial proposal
- updated proposal
- JointInferenceService controller enhancement
- FederatedLearning controller enhancement
I kept postponing a write-up until the controllers felt “done,” but later improvements diverged from the first attempt, so I’m recording versions separately. v1 is mostly from open-source summer work; it will differ from the proposals. As I learn more Kubernetes, KubeEdge, and Sedna, I hope to go deeper.
Goals
- Joint inference and federated learning did not cascade-delete children:
kubectl delete JointInferenceService/FederatedLearningJob **left dependent resources behind. - Editing CRs with
kubectl edit FederatedLearningJob/JointInferenceService **did not roll changes to managed pods. - We wanted manual or accidental pod deletes to be healed by recreation.
Cascade deletion
Cascade deletion in Kubernetes
Owner references tell the control plane how objects relate. Kubernetes uses them so deletes can clean up dependents—usually managed automatically. The garbage collector performs cascade deletion.
When an object is deleted, dependents whose metadata.ownerReferences point to it are deleted too (behavior is configurable; default true).
ownerReferences is an array of owners. When an owner disappears, it is removed from the array; when no owners remain, GC collects the object.
Knowing this, correct ownerReference values should fix missing cascades—if cascades fail, owner refs are wrong. Next step: trace job/pod creation code.
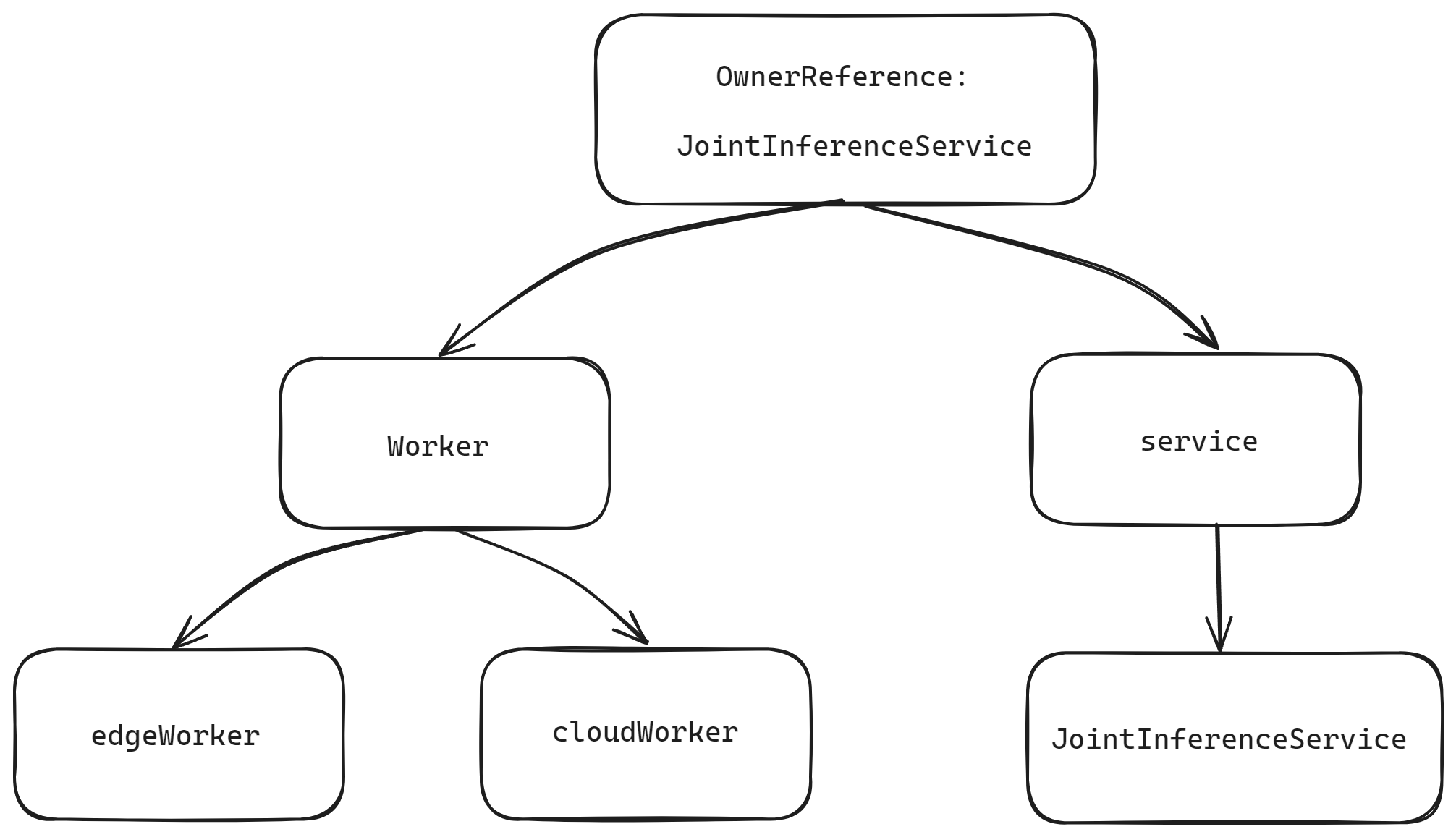
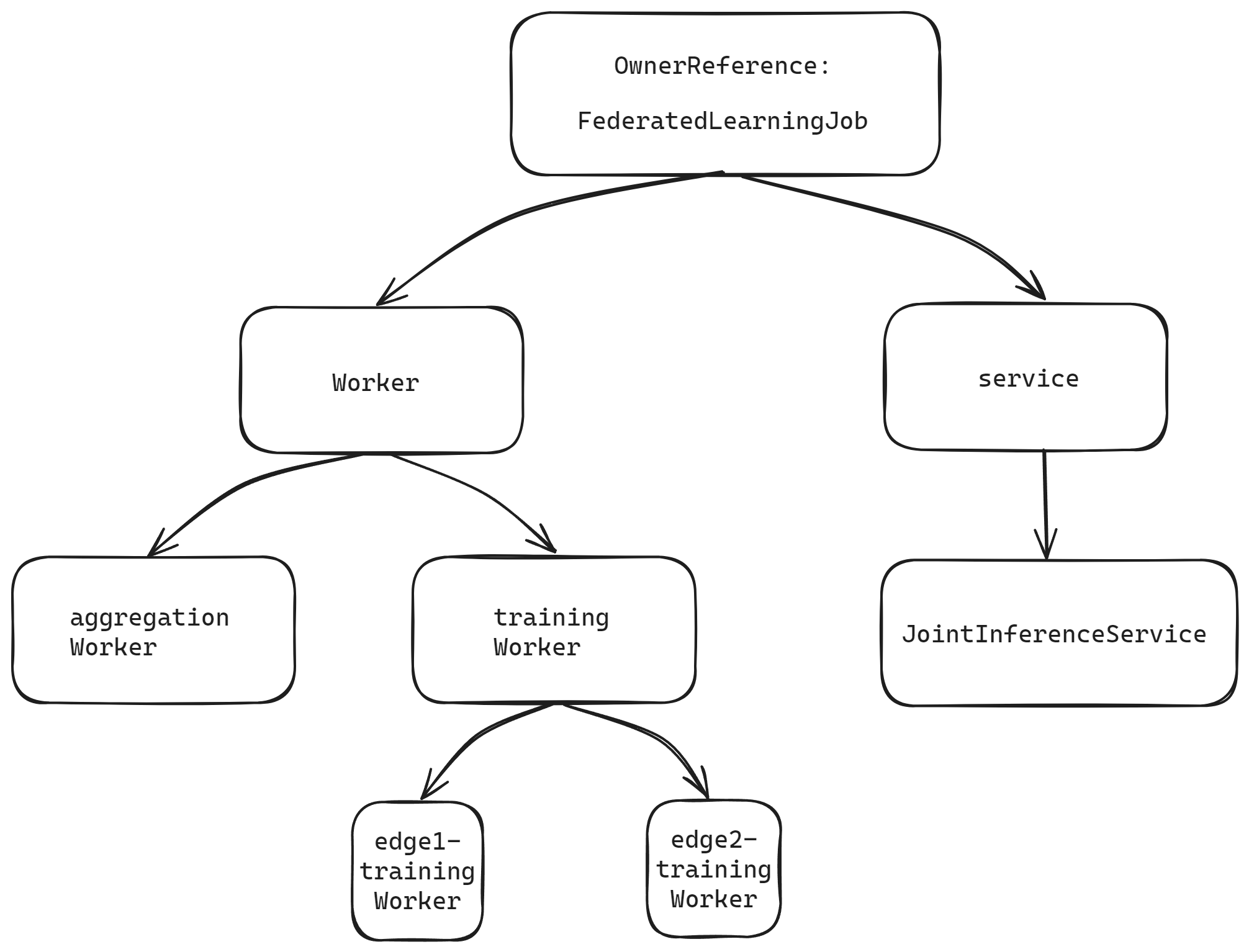
Owner references for joint inference vs federated learning
JointInferenceService (joint inference)
FederatedLearningJob (federated learning)
How the joint inference controller sets owner references
Using the joint inference controller as an example.
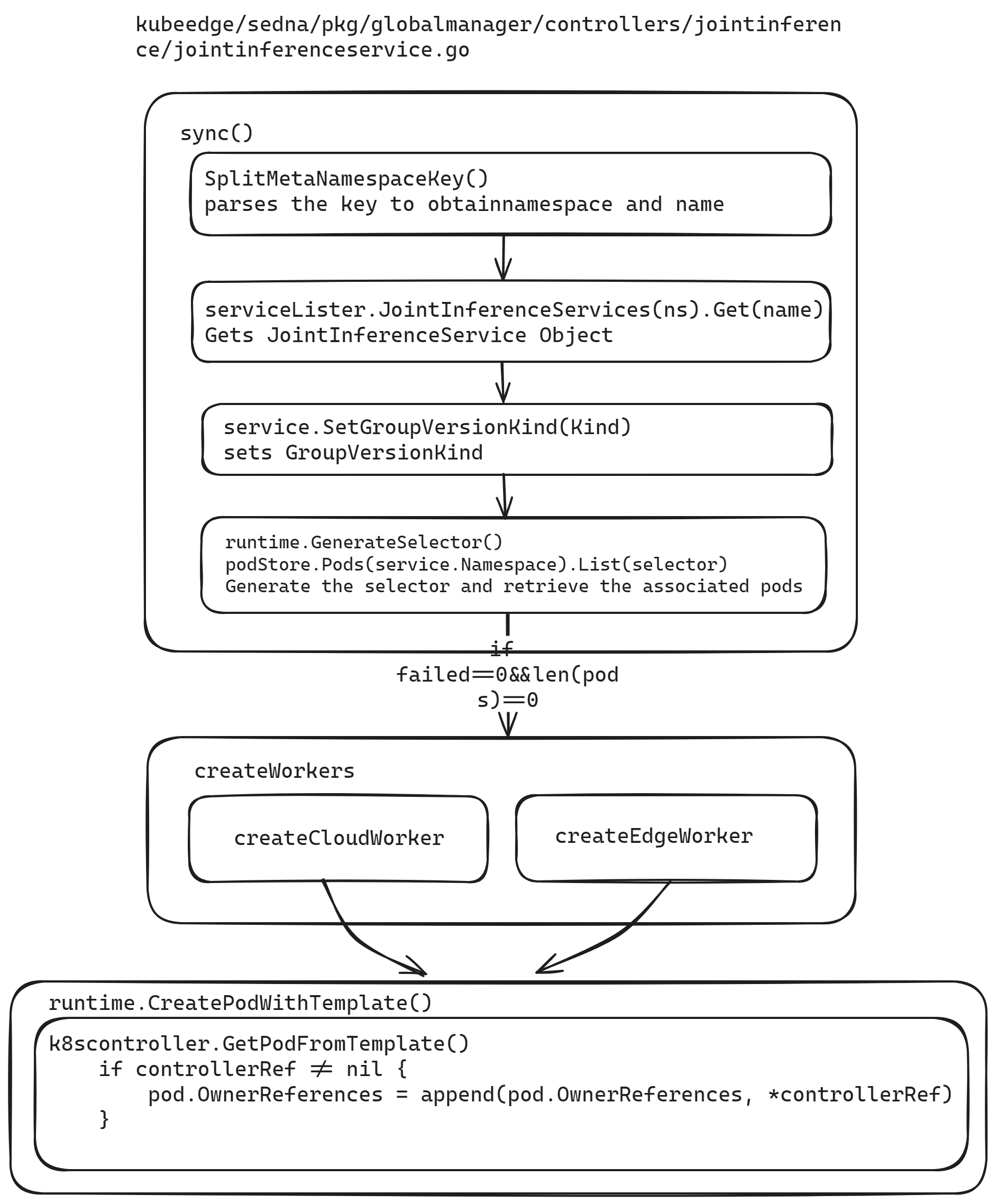
The wiring for owner references was fine—the bug was which value we passed.
In pkg/globalmanager/controllers/jointinference/jointinferenceservice.go we define the controller name and the CR Kind name. The owner reference must use the Kind name, not the internal controller name.
// Name is this controller name
Name = "JointInference"
// KindName is the kind name of CR this controller controls
KindName = "JointInferenceService"
Here we define the CR kind. Old code passed Name (JointInference) but should pass KindName (JointInferenceService).
// Kind contains the schema.GroupVersionKind for this controller type.
var Kind = sednav1.SchemeGroupVersion.WithKind(KindName)
run starts the controller: choose worker count, launch goroutines that call c.worker every second until stopCh closes.
for i := 0; i < workers; i++ { go wait.Until(c.worker, time.Second, stopCh) }
wait.Until runs c.worker on a one-second tick until stopCh closes.
// worker runs a worker thread that just dequeues items, processes them, and marks them done.
// It enforces that the sync is never invoked concurrently with the same key.
func (c *Controller) worker() {
for c.processNextWorkItem() {
}
}
worker loops processNextWorkItem(), which dequeues work and calls sync until the queue shuts down.
ns, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return false, err
}
if len(ns) == 0 || len(name) == 0 {
return false, fmt.Errorf("invalid jointinference service key %q: either namespace or name is missing", key)
}
In sync, cache.SplitMetaNamespaceKey parses namespace/name from the queue key.
sharedService, err := c.serviceLister.JointInferenceServices(ns).Get(name)
if err != nil {
if errors.IsNotFound(err) {
klog.V(4).Infof("JointInferenceService has been deleted: %v", key)
return true, nil
}
return false, err
}
service := *sharedService
Load the JointInferenceService from the lister.
service.SetGroupVersionKind(Kind)
Set GroupVersionKind.
selector, _ := runtime.GenerateSelector(&service)
pods, err := c.podStore.Pods(service.Namespace).List(selector)
if err != nil {
return false, err
}
klog.V(4).Infof("list jointinference service %v/%v, %v pods: %v", service.Namespace, service.Name, len(pods), pods)
Build a selector and list related pods. When there is no failing worker and zero pods exist, call createWorkers.
else {
if len(pods) == 0 {
active, manageServiceErr = c.createWorkers(&service)
}
createWorkers calls createCloudWorker and createEdgeWorker. Both use runtime.CreatePodWithTemplate; k8scontroller.GetPodFromTemplate sets OwnerReferences via:
if controllerRef != nil {
pod.OwnerReferences = append(pod.OwnerReferences, *controllerRef)
}
Pod recreation
Whether failed pods restart is governed by RestartPolicy.
JointInferenceService leaves RestartPolicy unset → default Always. During joint inference, if EdgeMesh is misconfigured so the edge cannot reach the cloud on port 5000 for the large model, the edge pod may restart in a loop. FederatedLearningJob sets OnFailure.
To recreate pods after deletion, you need the Kubernetes informer model.
Informers
Controllers talk to the API through informers, not raw watches on every read. Informers list+watch: initial LIST hydrates objects, then WATCH streams changes into a cache—faster reads, less apiserver load.
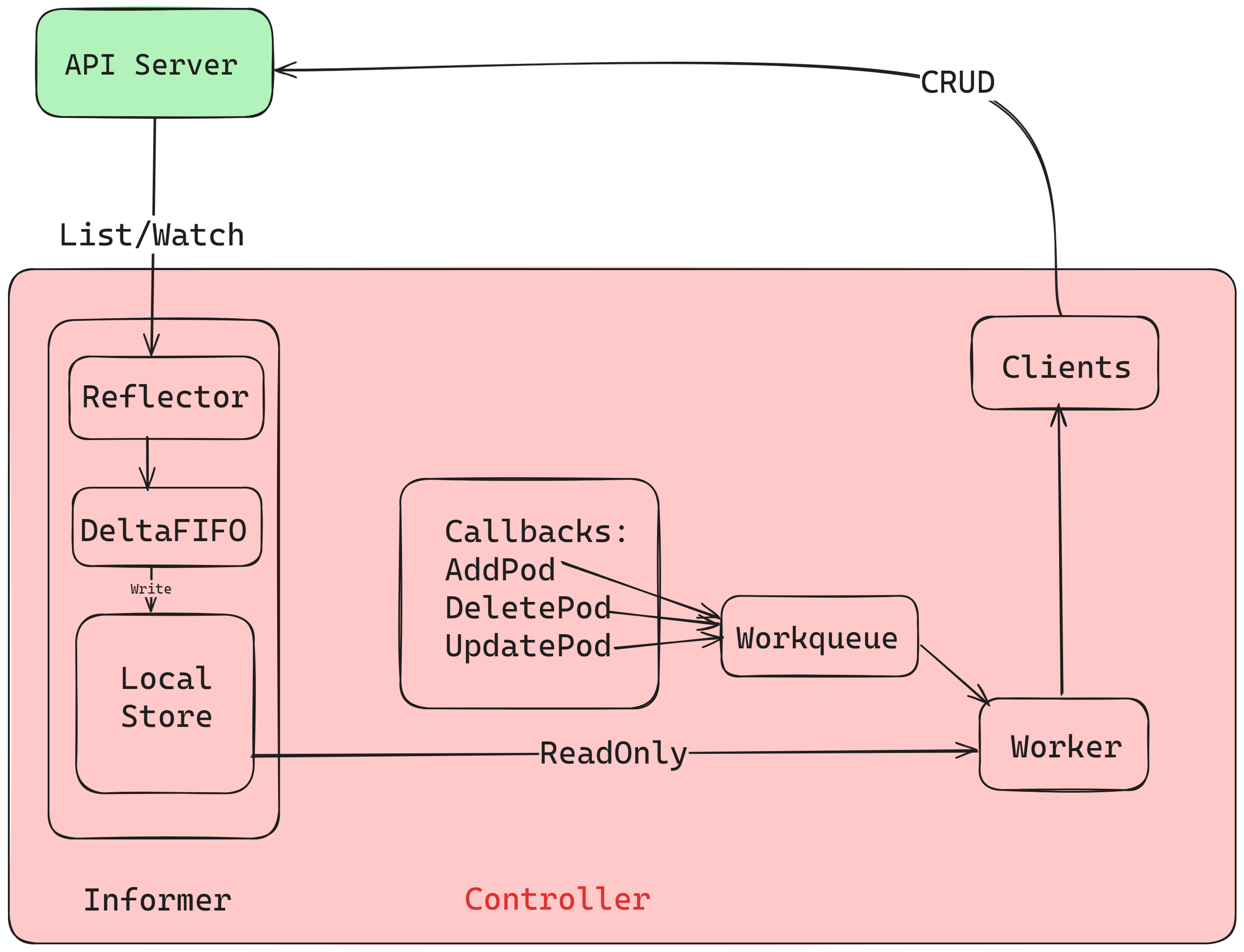
Roles in the diagram:
- Controller: drives reflectors and
processLoop; popsDeltaFIFO, updates the Indexer cache, notifies processors. - Reflector: performs ListWatch against apiserver; on Added/Updated/Deleted, pushes Deltas into
DeltaFIFO. - DeltaFIFO: FIFO queue of watch events (Added/Updated/Deleted).
- LocalStore / cache: snapshot of apiserver state (some objects may still be mid-flight in
DeltaFIFO); ListerList/Getread here. - WorkQueue: after the store updates, events move to a rate-limited work queue; the controller reacts per event type.
Informer lifecycle
Reflector lists all instances (records resourceVersion), then watches from that version; on errors it resumes from the last good RV. Each change becomes a Delta in DeltaFIFO.
The informer drains Deltas, updates the local store (Indexer), and forwards to registered ResourceEventHandlers—usually lightweight filters that enqueue keys.
Workers dequeue keys, run reconcile logic (desired vs actual), and call apiserver. Listers serve reads from cache instead of hammering apiserver.
ResourceEventHandler has three hooks:
// ResourceEventHandlerFuncs is an adaptor to let you easily specify as many or
// as few of the notification functions as you want while still implementing
// ResourceEventHandler.
type ResourceEventHandlerFuncs struct {
AddFunc func(obj interface{})
UpdateFunc func(oldObj, newObj interface{})
DeleteFunc func(obj interface{})
}
You implement these when constructing the controller; add/update/delete on the watched type fire the matching callback.
Informers in the joint inference / federated learning controllers
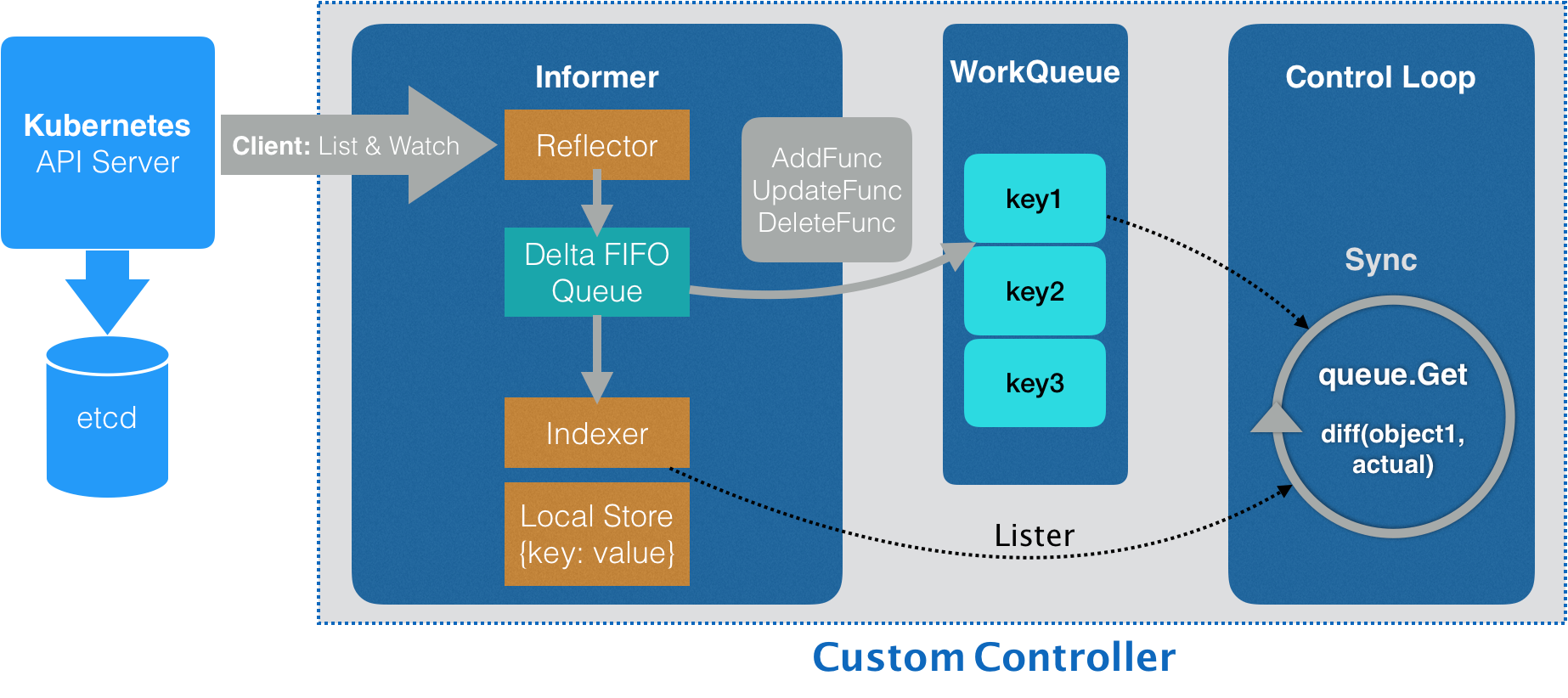
In jointinferenceservice.go, New() builds a controller that keeps pods aligned with JointInferenceService and wires informers:
podInformer := cc.KubeInformerFactory.Core().V1().Pods()
serviceInformer := cc.SednaInformerFactory.Sedna().V1alpha1().JointInferenceServices()
The service informer uses a custom handler:
serviceInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jc.enqueueController(obj, true)
jc.syncToEdge(watch.Added, obj)
},
UpdateFunc: func(old, cur interface{}) {
jc.enqueueController(cur, true)
jc.syncToEdge(watch.Added, cur)
},
DeleteFunc: func(obj interface{}) {
jc.enqueueController(obj, true)
jc.syncToEdge(watch.Deleted, obj)
},
})
The pod informer uses a custom handler:
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: jc.addPod,
UpdateFunc: jc.updatePod,
DeleteFunc: jc.deletePod,
})
addPod / updatePod / deletePod mainly enqueue objects—no heavy logic there.
podInformer.Lister() supplies pod reads; Informer().HasSynced gates on cache sync.
jc.serviceLister = serviceInformer.Lister()
jc.serviceStoreSynced = serviceInformer.Informer().HasSynced
//...
jc.podStore = podInformer.Lister()
jc.podStoreSynced = podInformer.Informer().HasSynced
Run() waits for caches to sync, then starts workers processing queue keys through sync.
if !cache.WaitForNamedCacheSync(Name, stopCh, c.podStoreSynced, c.serviceStoreSynced) {
klog.Errorf("failed to wait for %s caches to sync", Name)
return
}
func (c *Controller) worker() {
for c.processNextWorkItem() {
}
}
processNextWorkItem pops a key, calls sync, loads objects from listers, and applies controller logic.
Federated learning: pod recreation design
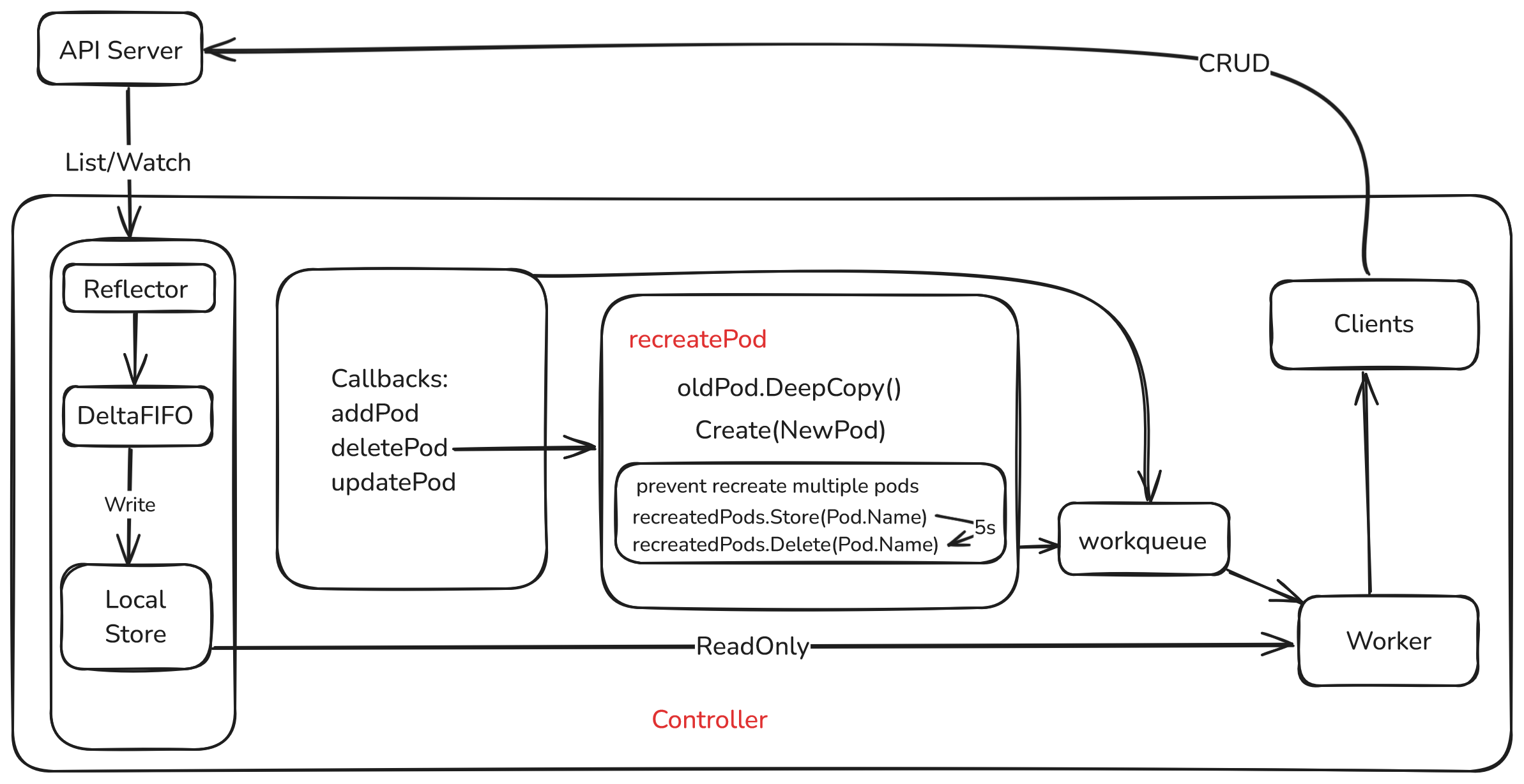
On pod delete events, if the pod was owned by a FederatedLearningJob, deletePod recreates a near-identical pod: same spec, fresh ResourceVersion / UID.
Logic
- Pre-checks
- Ensure the pod is owned by a
FederatedLearningJob. - Skip if
c.recreatedPods.Load(pod.Name)says we already recreated for this delete storm.
- Ensure the pod is owned by a
// first check if the pod is owned by a FederatedLearningJob
controllerRef := metav1.GetControllerOf(pod)
if controllerRef == nil || controllerRef.Kind != Kind.Kind {
return
}
- Recreate
pod.DeepCopy().- Clear
ResourceVersion,UID,Status, deletion timestamps/grace period. Createviac.kubeClient.CoreV1().Pods(pod.Namespace).Create.- On success, log and mark recreated.
// Create a deep copy of the old pod
newPod := pod.DeepCopy()
// Reset the resource version and UID as they are unique to each object
newPod.ResourceVersion = ""
newPod.UID = ""
// Clear the status
newPod.Status = v1.PodStatus{}
// Remove the deletion timestamp
newPod.DeletionTimestamp = nil
// Remove the deletion grace period seconds
newPod.DeletionGracePeriodSeconds = nil
_, err := c.kubeClient.CoreV1().Pods(pod.Namespace).Create(context.TODO(), newPod, metav1.CreateOptions{})
if err != nil {
return
}
- Dedup + timer
c.recreatedPods.Store(newPod.Name, true).- After 5s,
c.recreatedPods.Delete(pod.Name)so a later manual delete can trigger recreation again.
// mark the pod as recreated
c.recreatedPods.Store(newPod.Name, true)
// set a timer to delete the record from the map after a while
go func() {
time.Sleep(5 * time.Second)
c.recreatedPods.Delete(pod.Name)
}()
recreatedPods (sync.Map) prevents duplicate creates for the same delete burst. After a successful recreate, the name is recorded; if deletePod fires again immediately for the same name, we no-op. The timer clears the entry so future deletes work.
type Controller struct{
//...
preventRecreation bool
//...
}
Joint inference: pod recreation design
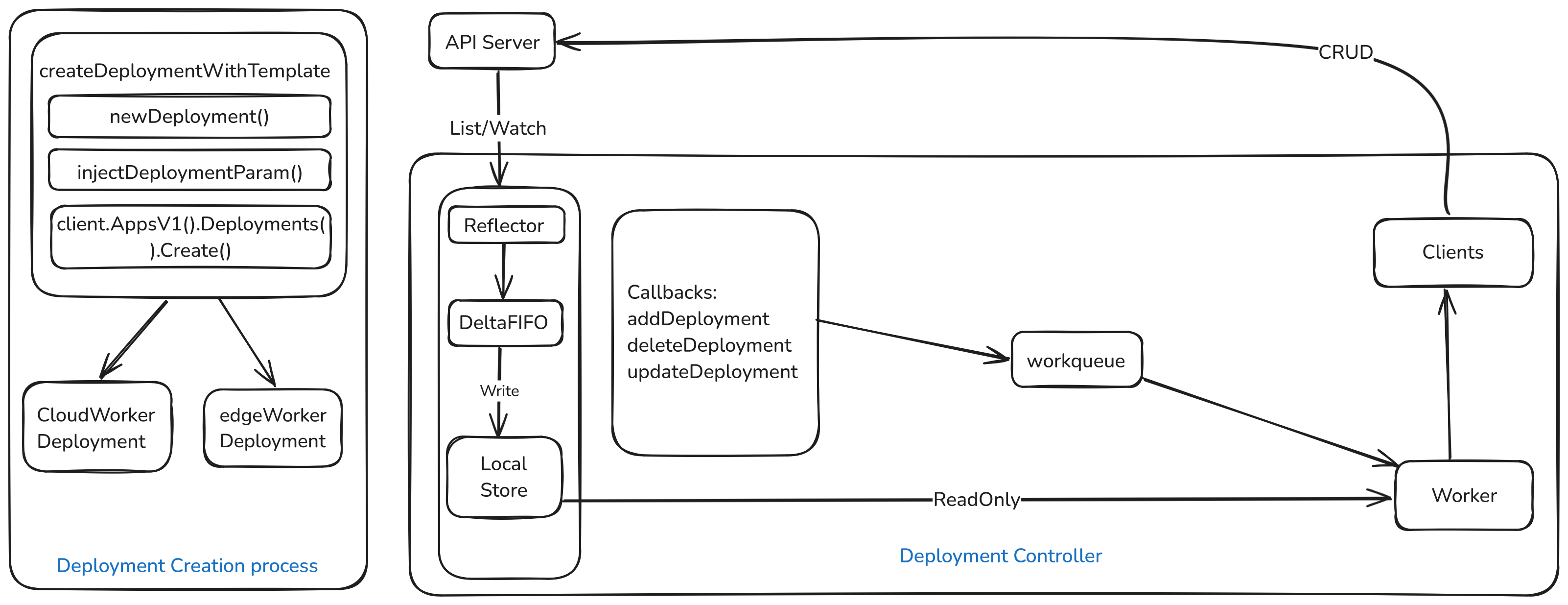
Inference workloads are effectively stateless; native Deployment self-healing applies. Wire a deployment informer with addDeployment / updateDeployment / deleteDeployment, wait for cache sync, then reconcile on Deployment changes.
Federated learning: CR edits roll to pods
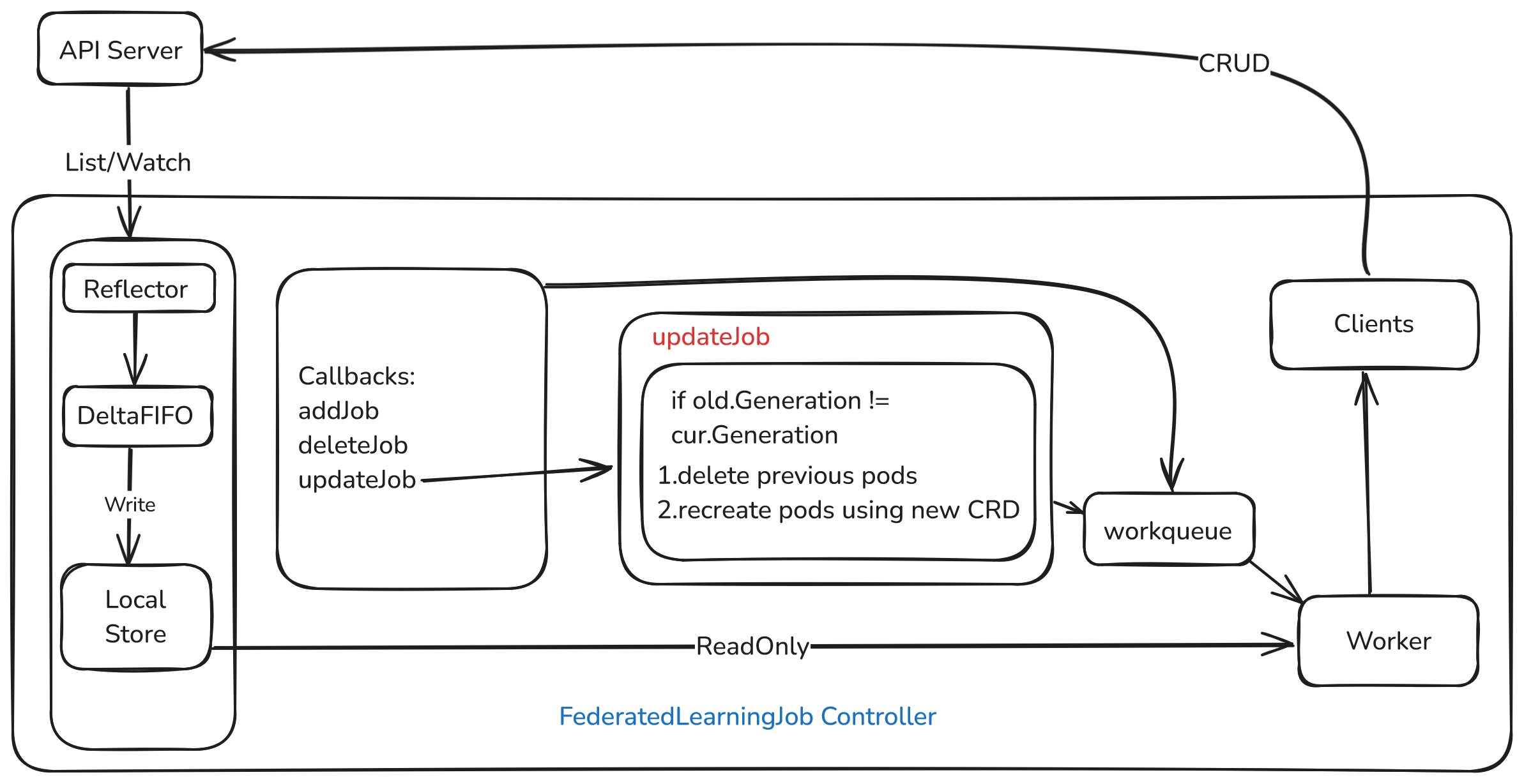
On FederatedLearningJob updates, if the spec changed, delete old pods and recreate from the new spec.
updateJob logic
- Bail if
old/curcannot cast tosednav1.FederatedLearningJob. - If
ResourceVersionunchanged, return. - Set
preventRecreation = trueto block recreate racing with update. - Compare
Generation: bumps on spec edits, not pure status churn. If generations differ, the job spec changed → delete listed pods → recreateAggWorker/TrainWorkerfromcurJob.Spec. - Clear
preventRecreationso normal self-heal resumes.
Joint inference: CR edits roll to pods
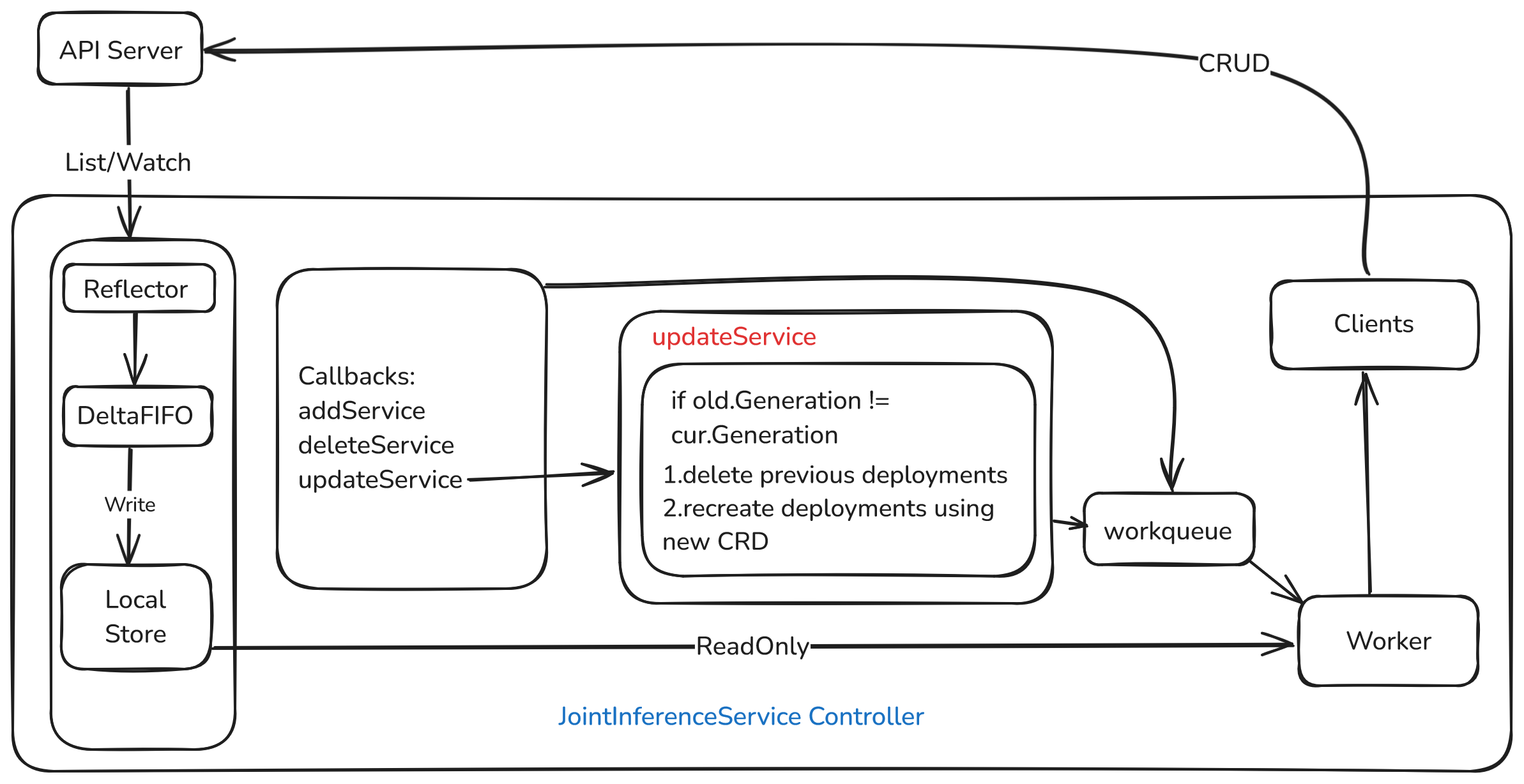
Same idea for JointInferenceService: on update, if spec (Generation) changed, delete pods and recreate cloudWorker / edgeWorker from curService.Spec.
updateService logic
Mirror federated learning: compare old.Generation vs cur.Generation; on change delete pods and rebuild workers from the new service spec.
Tests
Federated learning unit tests
Focus on deletePod and updateJob (unit tests, not e2e).
Test_deletePod
Recreate after delete
fake.NewSimpleClientset()client, seed a pod, controller with fake client.- Call
deletePod; assert pod exists again viafakeClient.CoreV1().Pods("default").Get(..., "test-pod", ...).
Delete missing pod
- Fake client + controller, call
deletePodon a non-existent pod, assert no unexpected error.
Test_updateJob
- Mock pod listing, fake client, datasets/models/job/pods.
- Initialize controller with fakes (including broadcaster deps).
- New job changes
TrainingWorker.batch_size32 → 16. - Run
updateJob(old, new)and assert updated fields match.
Joint inference unit tests
Test_UpdateService
- Fake Sedna + Kubernetes clients.
- Old service with cloud/edge worker config + two model CRs; derive Deployments/pods.
- Controller with fakes; stub
sendToEdgeFuncas no-op. - Clone service, bump
Generation, change edge HEM paramvalue1→value2. - Call
updateService, fetch updated service from fake client, assert HEM updated.