KubeEdge-Sedna源码解析(转载)-en
Original author: jaypume
Original lecture video: https://www.bilibili.com/video/BV1hg4y1b78L
Original article: https://github.com/jaypume/article/blob/main/sedna/边云协同AI框架Sedna源码解析/README.MD
Reposted for personal study and easier reference.
KubeEdge–Sedna overview
Sedna is an edge–cloud collaborative AI project incubated in the KubeEdge SIG AI. Building on KubeEdge’s edge–cloud capabilities, Sedna supports collaborative training and inference across edge and cloud—for example joint inference, incremental learning, federated learning, and lifelong learning. It works with widely used AI frameworks such as TensorFlow, PyTorch, and MindSpore, so existing AI workloads can migrate to Sedna with minimal friction to gain collaborative training and inference, with potential benefits in cost, model quality, and data privacy.
Project home:
https://github.com/kubeedge/sedna
Documentation:
https://sedna.readthedocs.io
Overall architecture
Sedna’s edge–cloud collaboration relies on the following KubeEdge capabilities:
- Unified orchestration of applications across edge and cloud
- Router: a reliable management-plane messaging channel between cloud and edge
- EdgeMesh: data-plane cross-edge–cloud service discovery and traffic management
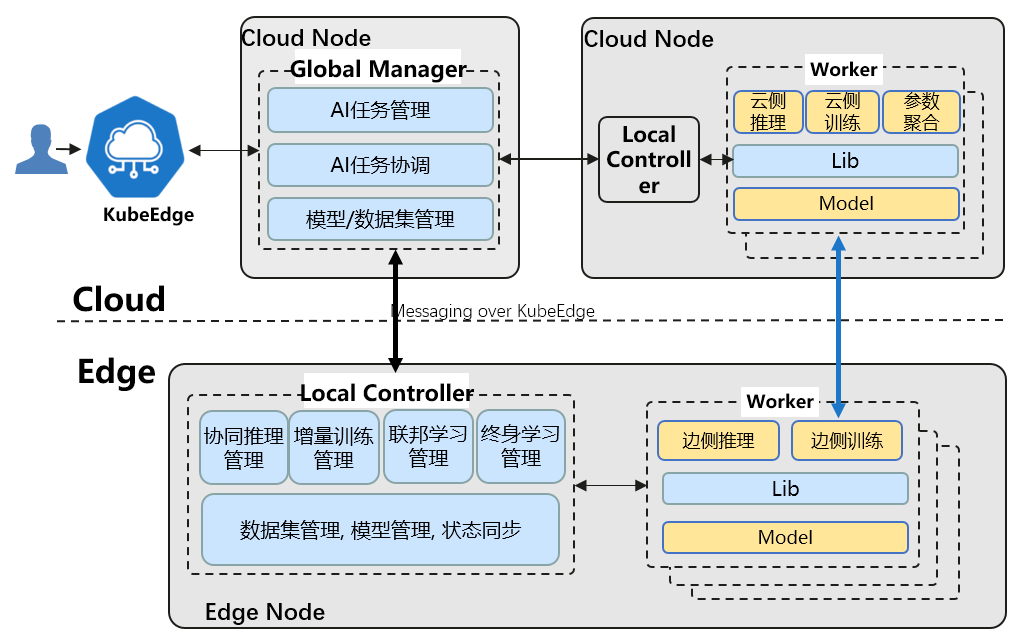
Core components:
- GlobalManager
- Unified management of edge–cloud collaborative AI jobs
- Cross-edge–cloud coordination and management
- Central configuration management
- LocalController
- Local control flow for collaborative AI jobs
- Local common management: models, datasets, status sync, etc.
- Lib
- For AI and application developers: exposes collaborative AI capabilities to applications
- Worker
- Runs training or inference jobs—training/inference programs built on existing AI frameworks
- Each feature maps to a worker group; workers can run on edge or cloud and cooperate
Repository layout
| Directory | Description |
|---|---|
| .github | Sedna GitHub CI/CD pipeline configuration. |
| LICENSES | Sedna licenses and related vendor licenses. |
| build | Dockerfiles for building GM/LC and other control-plane components; generated CRD YAML; sample CRD YAML. |
| cmd | Entrypoints for GM/LC control-plane binaries. |
| components | Monitoring and visualization components. |
| docs | Proposals and installation docs. |
| examples | Examples for joint inference, incremental learning, lifelong learning, and federated learning. |
| hack | Code generators and other scripts for developers. |
| lib | Sedna Library—Python dependency for building collaborative AI applications. |
| pkg | API definitions; generated client-go code for CRDs; core Sedna GM/LC control-plane code. |
| scripts | Installation scripts for users. |
| test | E2E tests and tooling. |
| vendor | Vendored third-party source. |
Sedna control plane source (Go)
GM: Global Manager
GM as a Kubernetes operator
What is an operator?
An Operator is an application-specific controller that extends the Kubernetes API to create, configure and manage instances of complex stateful applications on behalf of a Kubernetes user. It builds upon the basic Kubernetes resource and controller concepts, but also includes domain or application-specific knowledge to automate common tasks better managed by computers. [1]
For Sedna, the project governs how collaborative AI applications configure worker startup parameters, how they coordinate, and how data and artifacts flow. We can define it this way: Sedna GM is a domain-specific controller for “edge–cloud collaborative AI applications.”
The following components form the three main parts of an operator:
- API: The data that describes the operand’s configuration. The API includes:
- Custom resource definition (CRD), which defines a schema of settings available for configuring the operand.
- Programmatic API, which defines the same data schema as the CRD and is implemented using the operator’s programming language, such as Go.
- Custom resource (CR), which specifies values for the settings defined by the CRD; these values describe the configuration of an operand.
- Controller: The brains of the operator. The controller creates managed resources based on the description in the custom resource; controllers are implemented using the operator’s programming language, such as Go. [2]
From Red Hat’s definition, the main pieces of a Kubernetes operator are CRD, API, CR, and Controller.
The following diagram illustrates the Sedna GM operator:
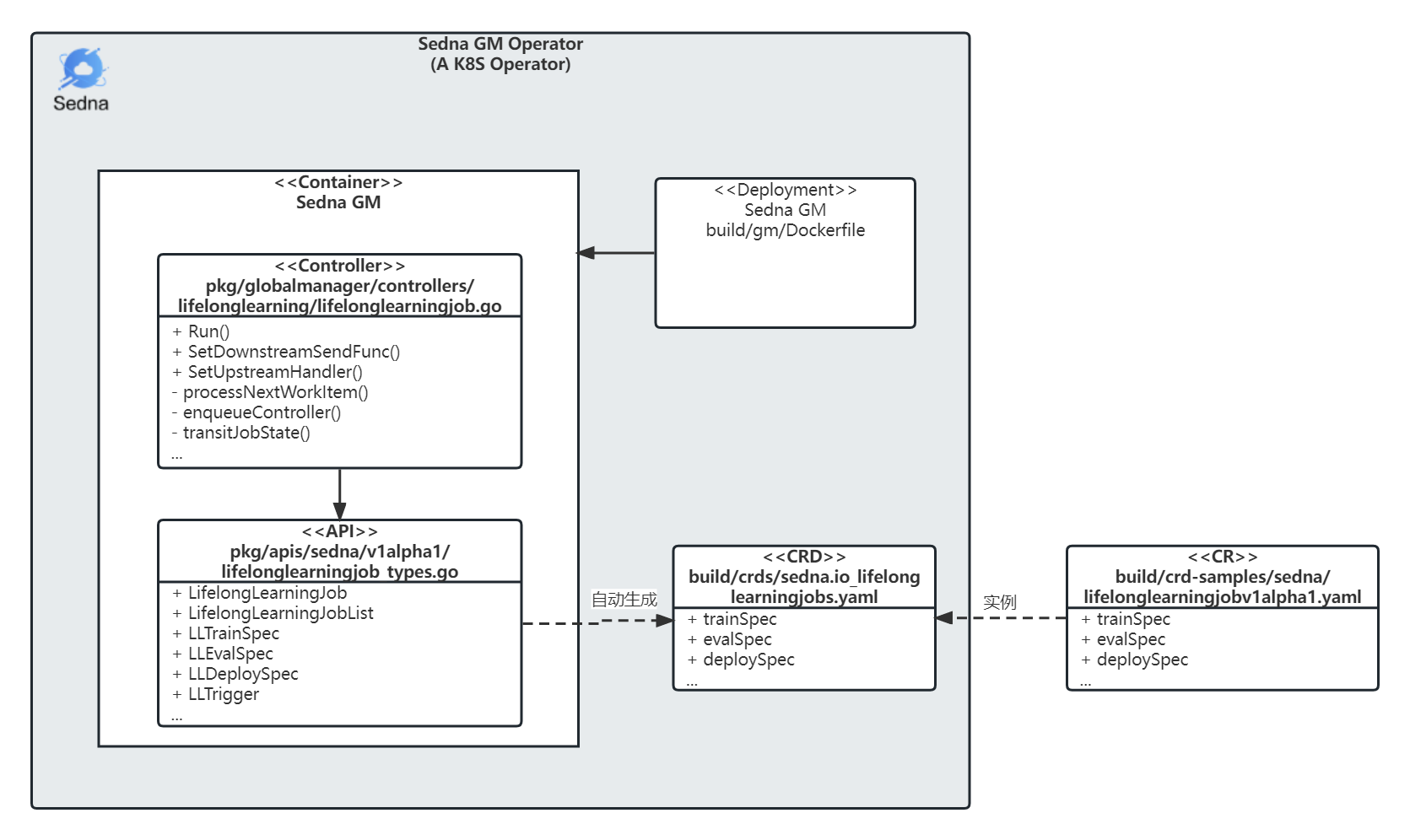
The following sections follow that breakdown—CR, CRD, API, and Controller—with Controller as the main control logic.
CR
Sedna supports collaborative inference, incremental learning, lifelong learning, and federated learning. For clarity, this article walks through lifelong learning using its concrete behavior and examples. The other three features share similar patterns in the codebase.
CR example
Below is a lifelong learning CR sample. You can create the corresponding lifelong learning object with kubectl from this CR; see this example for full steps. Important fields:
dataset: name of the dataset object (itself a CR).trainSpec: container settings for the training worker in lifelong learning—image, env, etc.trigger: conditions that start the training worker in lifelong learning.evalSpec: container settings for the evaluation worker—image, env, etc.deploySpec: container settings for the inference worker—image, env, etc.outputDir: where trained model artifacts are written in lifelong learning.
build/crd-samples/sedna/lifelonglearningjobv1alpha1.yaml
apiVersion: sedna.io/v1alpha1
kind: LifelongLearningJob
metadata:
name: atcii-classifier-demo
spec:
dataset:
name: "lifelong-dataset"
trainProb: 0.8
trainSpec:
template:
spec:
nodeName: "edge-node"
containers:
- image: kubeedge/sedna-example-lifelong-learning-atcii-classifier:v0.3.0
name: train-worker
imagePullPolicy: IfNotPresent
args: ["train.py"]
env:
- name: "early_stopping_rounds"
value: "100"
- name: "metric_name"
value: "mlogloss"
trigger:
checkPeriodSeconds: 60
timer:
start: 02:00
end: 24:00
condition:
operator: ">"
threshold: 500
metric: num_of_samples
evalSpec:
template:
spec:
nodeName: "edge-node"
containers:
- image: kubeedge/sedna-example-lifelong-learning-atcii-classifier:v0.3.0
name: eval-worker
imagePullPolicy: IfNotPresent
args: ["eval.py"]
env:
- name: "metrics"
value: "precision_score"
- name: "metric_param"
value: "{'average': 'micro'}"
- name: "model_threshold"
value: "0.5"
deploySpec:
template:
spec:
nodeName: "edge-node"
containers:
- image: kubeedge/sedna-example-lifelong-learning-atcii-classifier:v0.3.0
name: infer-worker
imagePullPolicy: IfNotPresent
args: ["inference.py"]
env:
- name: "UT_SAVED_URL"
value: "/ut_saved_url"
- name: "infer_dataset_url"
value: "/data/testData.csv"
volumeMounts:
- name: utdir
mountPath: /ut_saved_url
- name: inferdata
mountPath: /data/
resources:
limits:
memory: 2Gi
volumes:
- name: utdir
hostPath:
path: /lifelong/unseen_task/
type: DirectoryOrCreate
- name: inferdata
hostPath:
path: /data/
type: DirectoryOrCreate
outputDir: "/output"
CRD
A CRD is the template for CRs. Before you can create CRs of a kind, the CRD must be registered in the cluster. CRD YAML can be written by hand or generated; for complex CRDs, generation is recommended. Sedna uses kubebuilder’s controller-gen. The repo wraps this in scripts—run make crds to generate or refresh CRDs under build/crds/. See the crds: controller-gen target in Makefile.
A CRD must declare group, version, and kind—often shortened to GVK. CR instances are resources; loosely, Resource is like an object instance and Kind is like a class—so a Resource is an instance of a Kind. The table below maps lifelong learning CRD and CR to GVR/GVK:
| Group | Version | Resource | Kind | |
|---|---|---|---|---|
| CRD | apiextensions.k8s.io | v1 | lifelonglearningjobs.sedna.io | CustomResourceDefinition |
| CR | sedna.io | v1alpha1 | lifelonglearningjob | LifelongLearningJob |
In Kubernetes, resources are exposed via REST URIs organized as follows:

With these rules you can construct REST URIs for resources—useful when you cannot rely on kubectl or client-go. Examples:
Fetch the lifelong learning CRD via REST:
curl -k --cert ./client.crt --key ./client.key https://127.0.0.1:5443/apis/apiextensions.k8s.io/v1beta1/customresourcedefinitions/lifelonglearningjobs.sedna.io
List lifelong learning CRs via REST:
curl -k --cert ./client.crt --key ./client.key https://127.0.0.1:5443/apis/sedna.io/v1alpha1/lifelonglearningjobs
Languages without an official Kubernetes client can wrap these REST patterns uniformly.
Key fields in Sedna’s lifelong learning CRD:
apiVersion: apiextensions.k8s.io/v1— CRDs extend this API version.kind: CustomResourceDefinition— all CRDs use this kind.spec.group: sedna.io— API group for custom resources.spec.names.kind: LifelongLearningJob— the new resource type.spec.names.shortNames: - ll—kubectlshort name forLifelongLearningJob.
build/crds/sedna.io_lifelonglearningjobs.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
annotations:
controller-gen.kubebuilder.io/version: v0.4.1
creationTimestamp: null
name: lifelonglearningjobs.sedna.io
spec:
group: sedna.io
names:
kind: LifelongLearningJob
listKind: LifelongLearningJobList
plural: lifelonglearningjobs
shortNames:
- ll
singular: lifelonglearningjob
scope: Namespaced
versions:
- name: v1alpha1
...
status:
acceptedNames:
kind: ""
plural: ""
conditions: []
storedVersions: []
API
The CRDs are auto-generated—where do the underlying API definitions live?
pkg/apis/sedna/v1alpha1/lifelonglearningjob_types.go
package v1alpha1
import (
v1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
// Shown here:
// +genclient
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// +kubebuilder:resource:shortName=ll
// +kubebuilder:subresource:status
// LifelongLearningJob API definition: primarily Spec and Status—desired vs observed state.
type LifelongLearningJob struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata"`
Spec LLJobSpec `json:"spec"`
Status LLJobStatus `json:"status,omitempty"`
}
// Parameters required when creating a LifelongLearningJob; extend lifelong-learning fields here.
type LLJobSpec struct {
Dataset LLDataset `json:"dataset"`
TrainSpec LLTrainSpec `json:"trainSpec"`
EvalSpec LLEvalSpec `json:"evalSpec"`
DeploySpec LLDeploySpec `json:"deploySpec"`
// the credential referer for OutputDir
CredentialName string `json:"credentialName,omitempty"`
OutputDir string `json:"outputDir"`
}
type LLDataset struct {
Name string `json:"name"`
TrainProb float64 `json:"trainProb"`
}
// Additional struct definitions are omitted.
Takeaways from the snippet:
// +kubebuilder...— comments are inputs to kubebuilder and similar generators.type LifelongLearningJob struct{...}— top-level API for the CRD; holds Spec (desired) and Status (observed).type LLJobSpec struct {...}— fields for the CR; extend here when adding lifelong-learning parameters.
API types for joint inference, incremental learning, and federated learning live under pkg/apis/sedna/v1alpha1/.
Regenerate client-go code
After you add or change definitions in *_types.go, refresh generated clients:
bash hack/update-codegen.sh
Generated code is under pkg/client:
➜ pkg tree client -L 2
client
├── clientset
│ └── versioned
├── informers
│ └── externalversions
└── listers
└── sedna
These clients are used throughout Controller logic.
Regenerate CRD manifests
After API changes, refresh CRD YAML:
make crds
CRDs land in build/crds. Re-apply them to the cluster with kubectl apply so the cluster picks up changes.
Controller
The main lifelong-learning control logic lives in pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go—when train/eval workers run, how parameters sync to the edge, etc.
Before diving in, the overall call flow can be sketched as:
cmd/sedna-gm/sedna-gm.go/main() 【1】
pkg/globalmanager/controllers/manager.go/New() 【2】 load GM config.
pkg/globalmanager/controllers/manager.go/Start() 【3】 start GM.
- clientset.NewForConfig():【4】 build Sedna CRD client from client-go.
- NewUpstreamController():【5】 one UpstreamController per GM process
- uc.Run(stopCh): goroutine loop handling
- pkg/globalmanager/controllers/upstream.go/syncEdgeUpdate()
- NewRegistry():【6】 register all feature controllers.
- f.SetDownstreamSendFunc()【7】
-> pkg/globalmanager/controllers/lifelonglearning/downstream.go
- f.SetUpstreamHandler()【8】
-> pkg/globalmanager/controllers/lifelonglearning/upstream.go/updateFromEdge()
- f.Run()【9】
- ws.ListenAndServe() 【10】
The following subsections follow markers 【1】–【10】.
【1】 main entrypoint
sedna-gm.go is the GM binary entry: logging setup, app.NewControllerCommand() parses flags and starts GM controllers.
cmd/sedna-gm/sedna-gm.go
func main() {
rand.Seed(time.Now().UnixNano())
command := app.NewControllerCommand()
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
【2】 Load GM configuration
GM loads cluster config, WebSocket listen address/port, knowledge-base (KB) endpoints, etc.
pkg/globalmanager/controllers/manager.go
// New creates the controller manager
func New(cc *config.ControllerConfig) *Manager {
config.InitConfigure(cc)
return &Manager{
Config: cc,
}
}
pkg/globalmanager/config/config.go
// ControllerConfig indicates the config of controller
type ControllerConfig struct {
// KubeAPIConfig indicates the kubernetes cluster info which controller will connected
KubeConfig string `json:"kubeConfig,omitempty"`
// Master indicates the address of the Kubernetes API server. Overrides any value in KubeConfig.
// such as https://127.0.0.1:8443
// default ""
Master string `json:"master"`
// Namespace indicates which namespace the controller listening to.
// default ""
Namespace string `json:"namespace,omitempty"`
// websocket server config
// Since the current limit of kubeedge(1.5), GM needs to build the websocket channel for communicating between GM and LCs.
WebSocket WebSocket `json:"websocket,omitempty"`
// lc config to info the worker
LC LCConfig `json:"localController,omitempty"`
// kb config to info the worker
KB KBConfig `json:"knowledgeBaseServer,omitempty"`
// period config min resync period
// default 30s
MinResyncPeriodSeconds int64 `json:"minResyncPeriodSeconds,omitempty"`
}
【3】 GM startup sequence
Startup initializes the Sedna CRD client, wires edge–cloud messaging, starts per-feature controllers, and opens the WebSocket listener.
pkg/globalmanager/controllers/manager.go
// Start starts the controllers it has managed
func (m *Manager) Start() error {
...
// Initialize Sedna CRD client; controllers watch Sedna CR changes and react.
sednaClient, err := clientset.NewForConfig(kubecfg)
...
sednaInformerFactory := sednainformers.NewSharedInformerFactoryWithOptions(sednaClient, genResyncPeriod(minResyncPeriod), sednainformers.WithNamespace(namespace))
// UpstreamController handles messages uploaded from edge LCs
uc, _ := NewUpstreamController(context)
downstreamSendFunc := messagelayer.NewContextMessageLayer().SendResourceObject
stopCh := make(chan struct{})
go uc.Run(stopCh)
// For each feature (joint inference, lifelong learning, ...), bind message handlers
for name, factory := range NewRegistry() {
...
f.SetDownstreamSendFunc(downstreamSendFunc)
f.SetUpstreamHandler(uc.Add)
...
// Start that feature’s controller
go f.Run(stopCh)
}
...
// GM WebSocket server, default 0.0.0.0:9000
ws := websocket.NewServer(addr)
...
}
【4】 Initialize the CRD client
clientset.NewForConfig() is implemented in pkg/client/clientset/versioned/clientset.go—generated from the Sedna API types for typed CRUD.
New for the lifelong-learning controller does roughly:
- Obtain the
LifelongLearningJobinformer—a local cache backed by the API server to reduce load. - Wire controller fields: Kubernetes client, Sedna client, shared GM config.
- Register Add/Update/Delete handlers on
LifelongLearningJob.
pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go
// New creates a new LifelongLearningJob controller that keeps the relevant pods
// in sync with their corresponding LifelongLearningJob objects.
func New(cc *runtime.ControllerContext) (runtime.FeatureControllerI, error) {
cfg := cc.Config
podInformer := cc.KubeInformerFactory.Core().V1().Pods()
// LifelongLearningJob informer
jobInformer := cc.SednaInformerFactory.Sedna().V1alpha1().LifelongLearningJobs()
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: cc.KubeClient.CoreV1().Events("")})
// Controller fields
jc := &Controller{
kubeClient: cc.KubeClient,
client: cc.SednaClient.SednaV1alpha1(),
queue: workqueue.NewNamedRateLimitingQueue(workqueue.NewItemExponentialFailureRateLimiter(runtime.DefaultBackOff, runtime.MaxBackOff), Name),
cfg: cfg,
}
// LifelongLearningJob Add/Update/Delete callbacks
jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jc.enqueueController(obj, true)
jc.syncToEdge(watch.Added, obj)
},
UpdateFunc: func(old, cur interface{}) {
jc.enqueueController(cur, true)
jc.syncToEdge(watch.Added, cur)
},
DeleteFunc: func(obj interface{}) {
jc.enqueueController(obj, true)
jc.syncToEdge(watch.Deleted, obj)
},
})
jc.jobLister = jobInformer.Lister()
jc.jobStoreSynced = jobInformer.Informer().HasSynced
// Pod Add/Update/Delete callbacks
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: jc.addPod,
UpdateFunc: jc.updatePod,
DeleteFunc: jc.deletePod,
})
jc.podStore = podInformer.Lister()
jc.podStoreSynced = podInformer.Informer().HasSynced
return jc, nil
}
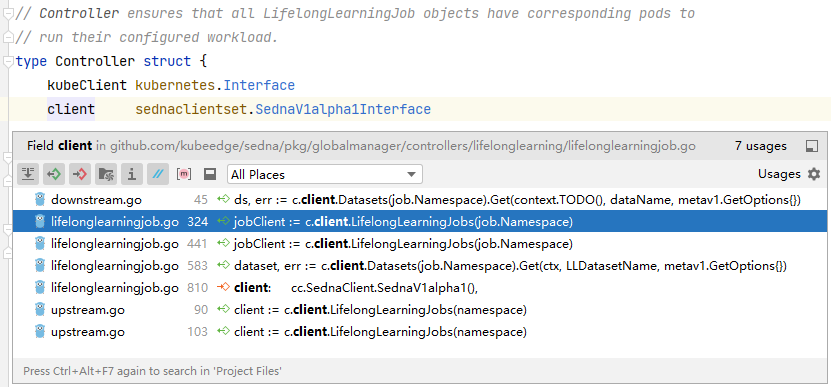
The screenshot below shows other modules referencing the Sedna CRD client.
【5】 Message handling setup
uc.Run() drives the UpstreamController, which processes all messages from edges. A loop reads context.upstreamChannel; on each message it looks up uc.updateHandlers[kind] and dispatches. That map holds handlers for joint inference, incremental learning, federated learning, lifelong learning, etc.
pkg/globalmanager/controllers/upstream.go
// syncEdgeUpdate receives the updates from edge and syncs these to k8s.
func (uc *UpstreamController) syncEdgeUpdate() {
for {
select {
case <-uc.messageLayer.Done():
klog.Info("Stop sedna upstream loop")
return
default:
}
update, err := uc.messageLayer.ReceiveResourceUpdate()
...
handler, ok := uc.updateHandlers[kind]
if ok {
err := handler(name, namespace, operation, update.Content)
...
}
}
}
ReceiveFromEdge blocks on a channel carrying nodeMessage values from edge LCs.
pkg/globalmanager/messagelayer/ws/context.go
// ReceiveResourceUpdate receives and handles the update
func (cml *ContextMessageLayer) ReceiveResourceUpdate() (*ResourceUpdateSpec, error) {
nodeName, msg, err := wsContext.ReceiveFromEdge()
...
}
【6】 Controller registry
NewRegistry() registers constructors for every feature; add a New function here when introducing a new collaborative capability.
pkg/globalmanager/controllers/registry.go
func NewRegistry() Registry {
return Registry{
ji.Name: ji.New,
fe.Name: fe.New,
fl.Name: fl.New,
il.Name: il.New,
ll.Name: ll.New,
reid.Name: reid.New,
va.Name: va.New,
dataset.Name: dataset.New,
objs.Name: objs.New,
}
}
【7】 Cloud → edge sync
f.SetDownstreamSendFunc() binds each feature’s syncToEdge() implementation.
For lifelong learning, syncing roughly:
- Resolve the node named on the
DatasetCR. - Read train/eval/deploy node names from annotations.
- Depending on the job stage, send to the appropriate node.
pkg/globalmanager/controllers/lifelonglearning/downstream.go
func (c *Controller) syncToEdge(eventType watch.EventType, obj interface{}) error {
// Dataset CR carries the target node name
ds, err := c.client.Datasets(job.Namespace).Get(context.TODO(), dataName, metav1.GetOptions{})
// Train / eval / deploy node names from annotations
getAnnotationsNodeName := func(nodeName sednav1.LLJobStage) string {
return runtime.AnnotationsKeyPrefix + string(nodeName)
}
ann := job.GetAnnotations()
if ann != nil {
trainNodeName = ann[getAnnotationsNodeName(sednav1.LLJobTrain)]
evalNodeName = ann[getAnnotationsNodeName(sednav1.LLJobEval)]
deployNodeName = ann[getAnnotationsNodeName(sednav1.LLJobDeploy)]
}
...
// Route by current stage
switch jobStage {
case sednav1.LLJobTrain:
doJobStageEvent(trainNodeName)
case sednav1.LLJobEval:
doJobStageEvent(evalNodeName)
case sednav1.LLJobDeploy:
doJobStageEvent(deployNodeName)
}
return nil
}
【8】 Edge → cloud sync
f.SetUpstreamHandler() binds each feature’s updateFromEdge().
For lifelong learning it:
- Updates aggregate
LifelongLearningJobstatus from per-edge progress. - Persists status to the API server (
Statuson the CR). - Parses JSON payloads from the edge—for example:
{
"phase": "train",
"status": "completed",
"output": {
"models": [{
"classes": ["road", "fence"],
"current_metric": null,
"format": "pkl",
"metrics": null,
"url": "/output/train/1/index.pkl"
}],
"ownerInfo": null
}
}
pkg/globalmanager/controllers/lifelonglearning/upstream.go
// updateFromEdge syncs the edge updates to k8s
func (c *Controller) updateFromEdge(name, namespace, operation string, content []byte) error {
var jobStatus struct {
Phase string `json:"phase"`
Status string `json:"status"`
}
// Parse edge JSON
err := json.Unmarshal(content, &jobStatus)
...
cond := sednav1.LLJobCondition{
Status: v1.ConditionTrue,
LastHeartbeatTime: metav1.Now(),
LastTransitionTime: metav1.Now(),
Data: string(condDataBytes),
Message: "reported by lc",
}
// Map edge status into LifelongLearningJob conditions
switch strings.ToLower(jobStatus.Status) {
case "ready":
cond.Type = sednav1.LLJobStageCondReady
case "completed":
cond.Type = sednav1.LLJobStageCondCompleted
case "failed":
cond.Type = sednav1.LLJobStageCondFailed
case "waiting":
cond.Type = sednav1.LLJobStageCondWaiting
default:
return fmt.Errorf("invalid condition type: %v", jobStatus.Status)
}
// Write back Status on the LifelongLearningJob CR
err = c.appendStatusCondition(name, namespace, cond)
...
}
【9】 Core controller loop
f.Run() starts each feature controller. For lifelong learning, Run() waits for informer sync, then starts worker goroutines.
pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go
// Run starts the main goroutine responsible for watching and syncing jobs.
func (c *Controller) Run(stopCh <-chan struct{}) {
workers := 1
defer utilruntime.HandleCrash()
defer c.queue.ShutDown()
klog.Infof("Starting %s controller", Name)
defer klog.Infof("Shutting down %s controller", Name)
if !cache.WaitForNamedCacheSync(Name, stopCh, c.podStoreSynced, c.jobStoreSynced) {
klog.Errorf("failed to wait for %s caches to sync", Name)
return
}
klog.Infof("Starting %s workers", Name)
for i := 0; i < workers; i++ {
go wait.Until(c.worker, time.Second, stopCh)
}
<-stopCh
}
worker calls processNextWorkItem() so syncHandler never runs the same key concurrently.
pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go
// worker runs a worker thread that just dequeues items, processes them, and marks them done.
// It enforces that the syncHandler is never invoked concurrently with the same key.
func (c *Controller) worker() {
for c.processNextWorkItem() {
}
}
processNextWorkItem() invokes sync().
pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go
func (c *Controller) sync(key string) (bool, error) {
// Part of the implementation omitted
ns, name, err := cache.SplitMetaNamespaceKey(key)
sharedJob, err := c.jobLister.LifelongLearningJobs(ns).Get(name)
// if job was finished previously, we don't want to redo the termination
if IsJobFinished(&job) {
return true, nil
}
// transit this job's state machine
needUpdated, err = c.transitJobState(&job)
if needUpdated {
if err := c.updateJobStatus(&job); err != nil {
return forget, err
}
if jobFailed && !IsJobFinished(&job) {
// returning an error will re-enqueue LifelongLearningJob after the backoff period
return forget, fmt.Errorf("failed pod(s) detected for lifelonglearningjob key %q", key)
}
forget = true
}
return forget, err
}
sync handles a single job:
- Split the work-queue key into namespace and name.
- Load the
LifelongLearningJobvia the lister. transitJobStateadvances train → eval → deploy as appropriate.- If status changed,
updateJobStatuswrites it back sokubectlreflects current phase, model paths, etc. - Handle failures and retries.
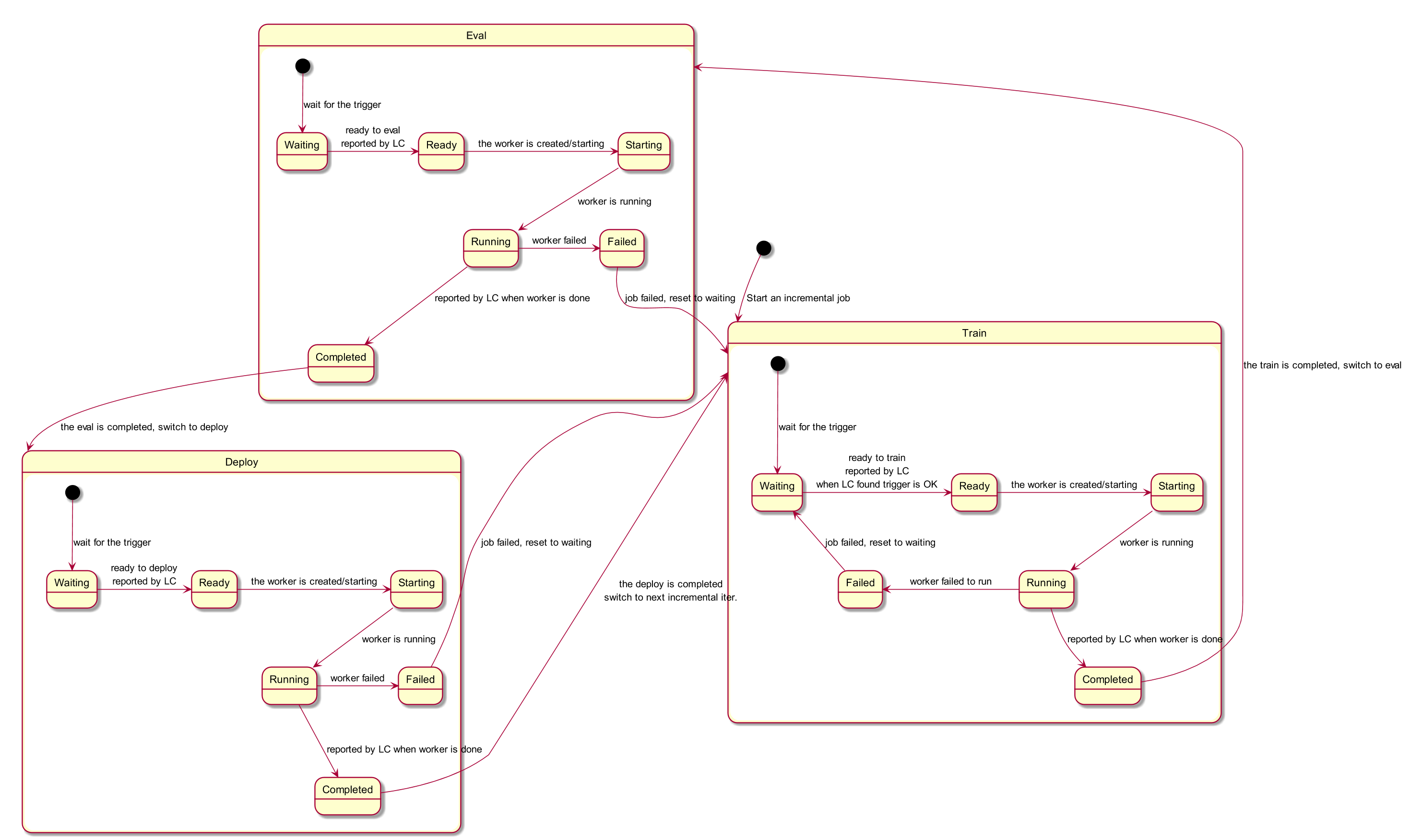
// transit this job's state machine
needUpdated, err = c.transitJobState(&job)
transitJobState() is the state machine—when each stage starts/stops. Use the diagram below together with the code.
【10】 WebSocket server
GM listens for edge messages (as in 【8】), defaulting to 0.0.0.0:9000.
pkg/globalmanager/controllers/manager.go
addr := fmt.Sprintf("%s:%d", m.Config.WebSocket.Address, m.Config.WebSocket.Port)
ws := websocket.NewServer(addr)
err = ws.ListenAndServe()
LC: Local Controller
LC runs on edge nodes for local job management and message relaying. The binary entry is cmd/sedna-lc/sedna-lc.go (same pattern as GM). Below is where feature managers are registered:
cmd/sedna-lc/app/server.go
// runServer runs server
func runServer() {
c := gmclient.NewWebSocketClient(Options)
if err := c.Start(); err != nil {
return
}
dm := dataset.New(c, Options)
mm := model.New(c)
jm := jointinference.New(c)
fm := federatedlearning.New(c)
im := incrementallearning.New(c, dm, mm, Options)
lm := lifelonglearning.New(c, dm, Options)
s := server.New(Options)
for _, m := range []managers.FeatureManager{
dm, mm, jm, fm, im, lm,
} {
s.AddFeatureManager(m)
c.Subscribe(m)
err := m.Start()
if err != nil {
klog.Errorf("failed to start manager %s: %v",
m.GetName(), err)
return
}
klog.Infof("manager %s is started", m.GetName())
}
s.ListenAndServe()
}
Local job management
The Manager struct models edge-side job management:
pkg/localcontroller/managers/lifelonglearning/lifelonglearningjob.go
// LifelongLearningJobManager defines lifelong-learning-job Manager
type Manager struct {
Client clienttypes.ClientI
WorkerMessageChannel chan workertypes.MessageContent
DatasetManager *dataset.Manager
LifelongLearningJobMap map[string]*Job
VolumeMountPrefix string
}
startJob() illustrates the flow:
- Watch synced
Datasetobjects—for example trigger training when sample count crosses a threshold. - Per stage, drive train/eval/deploy by reporting state up to GM; GM schedules the actual workloads rather than LC starting pods directly.
pkg/localcontroller/managers/lifelonglearning/lifelonglearningjob.go
// startJob starts a job
func (lm *Manager) startJob(name string) {
...
// Watch Dataset CRs synced to the edge
go lm.handleData(job)
tick := time.NewTicker(JobIterationIntervalSeconds * time.Second)
for {
// Drive train/eval/deploy by stage
select {
case <-job.JobConfig.Done:
return
case <-tick.C:
cond := lm.getLatestCondition(job)
jobStage := cond.Stage
switch jobStage {
case sednav1.LLJobTrain:
err = lm.trainTask(job)
case sednav1.LLJobEval:
err = lm.evalTask(job)
case sednav1.LLJobDeploy:
err = lm.deployTask(job)
default:
klog.Errorf("invalid phase: %s", jobStage)
continue
}
...
}
}
}
Beyond orchestration, LC also covers dataset monitoring, model downloads, and local persistence.
Message proxy
Besides pushing status to the cloud, LC serves HTTP on 0.0.0.0:9100, aggregating messages from the Lib SDK before forwarding to GM. Route registration:
pkg/localcontroller/server/server.go
// register registers api
func (s *Server) register(container *restful.Container) {
ws := new(restful.WebService)
ws.Path(fmt.Sprintf("/%s", constants.ServerRootPath)).
Consumes(restful.MIME_XML, restful.MIME_JSON).
Produces(restful.MIME_JSON, restful.MIME_XML)
ws.Route(ws.POST("/workers/{worker-name}/info").
To(s.messageHandler).
Doc("receive worker message"))
container.Add(ws)
}
pkg/localcontroller/server/server.go
// messageHandler handles message from the worker
func (s *Server) messageHandler(request *restful.Request, response *restful.Response) {
var err error
workerName := request.PathParameter("worker-name")
workerMessage := workertypes.MessageContent{}
err = request.ReadEntity(&workerMessage)
if workerMessage.Name != workerName || err != nil {
var msg string
if workerMessage.Name != workerName {
msg = fmt.Sprintf("worker name(name=%s) in the api is different from that(name=%s) in the message body",
workerName, workerMessage.Name)
} else {
msg = fmt.Sprintf("read worker(name=%s) message body failed, error: %v", workerName, err)
}
klog.Errorf(msg)
err = s.reply(response, http.StatusBadRequest, msg)
if err != nil {
klog.Errorf("reply messge to worker(name=%s) failed, error: %v", workerName, err)
}
}
if m, ok := s.fmm[workerMessage.OwnerKind]; ok {
m.AddWorkerMessage(workerMessage)
}
err = s.reply(response, http.StatusOK, "OK")
if err != nil {
klog.Errorf("reply message to worker(name=%s) failed, error: %v", workerName, err)
return
}
}
Sedna Lib source (Python)
Lib is the Python SDK for AI and application developers to adapt existing code to edge–cloud collaboration.
Directory layout:
➜ sedna tree lib -L 2
lib
├── __init__.py
├── MANIFEST.in
├── OWNERS
├── requirements.dev.txt
├── requirements.txt // Sedna Python dependencies
├── sedna
│ ├── algorithms // Collaborative algorithms
│ ├── backend // Backends: TensorFlow, PyTorch, ...
│ ├── common
│ ├── core // Feature implementations
│ ├── datasources // Formats such as txt, csv
│ ├── __init__.py
│ ├── README.md
│ ├── service // Components that run servers (e.g. KB)
│ ├── VERSION
│ └── __version__.py
└── setup.py
Highlights by area:
core
core wraps user callbacks. The train path below wires post-processing, cloud knowledge-base training/inference, KB updates (lifelong learning continuously refreshes models and samples), and LC reporting (completion, metrics).
lib/sedna/core/lifelong_learning/lifelong_learning.py
def train(self, train_data,
valid_data=None,
post_process=None,
**kwargs):
is_completed_initilization = \
str(Context.get_parameters("HAS_COMPLETED_INITIAL_TRAINING",
"false")).lower()
if is_completed_initilization == "true":
return self.update(train_data,
valid_data=valid_data,
post_process=post_process,
**kwargs)
# Configure post-processing callback
callback_func = None
if post_process is not None:
callback_func = ClassFactory.get_cls(
ClassType.CALLBACK, post_process)
res, seen_task_index = \
self.cloud_knowledge_management.seen_estimator.train(
train_data=train_data,
valid_data=valid_data,
**kwargs
)
# Train against cloud knowledge base (seen + unseen paths)
unseen_res, unseen_task_index = \
self.cloud_knowledge_management.unseen_estimator.train()
# Refresh cloud KB indices
task_index = dict(
seen_task=seen_task_index,
unseen_task=unseen_task_index)
task_index_url = FileOps.dump(
task_index, self.cloud_knowledge_management.local_task_index_url)
task_index = self.cloud_knowledge_management.update_kb(task_index_url)
res.update(unseen_res)
...
# Report status to LC (completion, metrics, ...)
self.report_task_info(
None, K8sResourceKindStatus.COMPLETED.value, task_info_res)
self.log.info(f"Lifelong learning Train task Finished, "
f"KB index save in {task_index}")
return callback_func(self.estimator, res) if callback_func else res
...
backend
MSBackend shows how Sedna plugs in MindSpore: implement train, predict, and evaluate and Lib can treat a framework as a backend, enabling thin wrappers around existing AI code for collaboration.
lib/sedna/backend/mindspore/__init__.py
class MSBackend(BackendBase):
def __init__(self, estimator, fine_tune=True, **kwargs):
super(MSBackend, self).__init__(estimator=estimator,
fine_tune=fine_tune,
**kwargs)
self.framework = "mindspore"
if self.use_npu:
context.set_context(mode=context.GRAPH_MODE,
device_target="Ascend")
elif self.use_cuda:
context.set_context(mode=context.GRAPH_MODE,
device_target="GPU")
else:
context.set_context(mode=context.GRAPH_MODE,
device_target="CPU")
if callable(self.estimator):
self.estimator = self.estimator()
def train(self, train_data, valid_data=None, **kwargs):
if callable(self.estimator):
self.estimator = self.estimator()
if self.fine_tune and FileOps.exists(self.model_save_path):
self.finetune()
self.has_load = True
varkw = self.parse_kwargs(self.estimator.train, **kwargs)
return self.estimator.train(train_data=train_data,
valid_data=valid_data,
**varkw)
def predict(self, data, **kwargs):
if not self.has_load:
self.load()
varkw = self.parse_kwargs(self.estimator.predict, **kwargs)
return self.estimator.predict(data=data, **varkw)
def evaluate(self, data, **kwargs):
if not self.has_load:
self.load()
varkw = self.parse_kwargs(self.estimator.evaluate, **kwargs)
return self.estimator.evaluate(data, **varkw)
datasource
datasource packages common dataset parsers so callers avoid boilerplate.
lib/sedna/datasources/__init__.py
class CSVDataParse(BaseDataSource, ABC):
"""
csv file which contain Structured Data parser
"""
# Helpers to parse tabular datasets
def parse(self, *args, **kwargs):
x_data = []
y_data = []
label = kwargs.pop("label") if "label" in kwargs else ""
usecols = kwargs.get("usecols", "")
if usecols and isinstance(usecols, str):
usecols = usecols.split(",")
if len(usecols):
if label and label not in usecols:
usecols.append(label)
kwargs["usecols"] = usecols
for f in args:
if isinstance(f, (dict, list)):
res = self.parse_json(f, **kwargs)
else:
if not (f and FileOps.exists(f)):
continue
res = pd.read_csv(f, **kwargs)
if self.process_func and callable(self.process_func):
res = self.process_func(res)
if label:
if label not in res.columns:
continue
y = res[label]
y_data.append(y)
res.drop(label, axis=1, inplace=True)
x_data.append(res)
if not x_data:
return
self.x = pd.concat(x_data)
self.y = pd.concat(y_data)
algorithms
Sedna ships algorithms tuned for edge–cloud settings—for example cross-entropy thresholding to flag low-confidence detections. The goal is not only bundled baselines but an extensible surface for new algorithms that improve end-to-end training and inference.
lib/sedna/algorithms/hard_example_mining/hard_example_mining.py
@ClassFactory.register(ClassType.HEM, alias="CrossEntropy")
class CrossEntropyFilter(BaseFilter, abc.ABC):
"""
**Object detection** Hard samples discovery methods named `CrossEntropy`
Parameters
----------
threshold_cross_entropy: float
hard coefficient threshold score to filter img, default to 0.5.
"""
def __init__(self, threshold_cross_entropy=0.5, **kwargs):
self.threshold_cross_entropy = float(threshold_cross_entropy)
def __call__(self, infer_result=None) -> bool:
"""judge the img is hard sample or not.
Parameters
----------
infer_result: array_like
prediction classes list, such as
[class1-score, class2-score, class2-score,....],
where class-score is the score corresponding to the class,
class-score value is in [0,1], who will be ignored if its
value not in [0,1].
Returns
-------
is hard sample: bool
`True` means hard sample, `False` means not.
"""
if not infer_result:
# if invalid input, return False
return False
log_sum = 0.0
data_check_list = [class_probability for class_probability
in infer_result
if self.data_check(class_probability)]
if len(data_check_list) != len(infer_result):
return False
for class_data in data_check_list:
log_sum += class_data * math.log(class_data)
confidence_score = 1 + 1.0 * log_sum / math.log(
len(infer_result))
return confidence_score < self.threshold_cross_entropy