休眠容器:一种用于快速启动和高密度部署的瘦身容器模式,适用于无服务器计算-en
English title: Hibernate Container: A Deflated Container Mode for Fast Startup and High-density Deployment in Serverless Computing
0 Abstract
Serverless computing is a popular cloud model that demands low response latency for on-demand requests. Two prominent techniques reduce latency: keep fully initialized containers warm (“hot containers”1) or cut cold-start time. This paper proposes a third mode—hibernate containers2: faster than cold start, far less memory than keeping hot containers resident. A hibernate container is essentially a deflated hot container: application memory is swapped to disk, freed pages are reclaimed, and file-backed mmap regions are dropped. When user traffic returns, the deflated memory is inflated again. Because the app is already initialized, latency beats cold start; because memory was deflated, footprint beats hot. When “awakened” for a request, latency is close to hot while memory stays lower—not every deflated page must be reinflated immediately. Implemented in the open-source Quark secure-container runtime, evaluation shows hibernate memory at roughly 7–25% of hot, improving density, latency, and overall performance.
1 Introduction
Serverless—FaaS and serverless containers—is now a mainstream cloud pattern. Multi-tenant platforms field bursty, on-demand workloads, backed by hyperscalers: AWS Lambda/Fargate, Google Cloud Functions/Cloud Run, Azure Functions/Container Instances, etc.
To isolate tenants, providers often use VM-class secure runtimes instead of process-based runtimes like runC/LXC. Examples: AWS Firecracker, GCP gVisor, and Kata on Alibaba/Huawei clouds. These trade stronger isolation for higher memory and latency versus process-based containers.
Latency matters: it includes runtime startup, application init, and request handling. Runtime startup is ~100 ms class; app init spans ~10 ms–10 s; request work is often ms–tens of ms. Compared with handling time, startup + init are huge. Two classic strategies:
- Warm-path tuning — keep runtimes hot for a while so repeat calls reuse containers. That cuts cold cost but burns RAM; the paper cites efforts to shrink runtime overhead and smarter keep-alive policies.
- Cold-start reduction — shrink runtime boot and app initialization (cited refs).
This paper’s third lever is swap-friendly hibernation, motivated by:
- Fast swap media — SSD/NVM makes paging far more viable.
- Small serverless footprints — e.g. 47% of AWS Lambda functions stick to the 128 MB default; only ~14% exceed 512 MB; on Azure 90% never pass 400 MB and half cap at ≤170 MB. Small working sets mean swap is affordable.
Together, swap + warm containers can yield low latency and low idle memory. Hibernate containers are deflated hot containers that:
- Memory — swap app memory out, return freed pages to the host, drop file-backed
mmappages viamadvise. - CPU — user apps are fully paused, so no active CPU while hibernating.
Response latency beats cold start because the app is initialized and host objects stay live:
- Host objects — runtime processes, cgroups, networking, filesystems, process tables: tiny RAM, big savings vs rebuilding.
- Blocked runtime threads — waiting on I/O like hot containers, but without spinning CPU.
After wake, later requests see hot-like latency with less RAM because not every page reinflates at once.
Contributions
- Hibernate mode in Quark: less memory than hot, faster than cold; awakened containers stay near-hot latency with smaller footprint.
- Major swap-in cost is random SSD reads; inspired by REAP, they add batched prefetch during inflation and compare fault-driven vs REAP swap-in.
- A reclamation-oriented allocator returns free pages to the host without ballooning complexity.
Ballooning (note) — A paravirtual trick: a “balloon” inside the guest holds memory the host can reclaim under pressure; inflating the balloon frees pages for the host; deflating returns RAM to the guest. Useful but operationally heavy.
2 Background and motivation
Hibernate containers are deflated hot Quark containers: reclaim freed app memory and swap the rest. This section sketches secure-container landscape, guest free-memory return, guest swapping, and why serverless is a sweet spot.
2.1 Secure containers and Quark
Hibernate ships inside Quark ([18]). VM-grade runtimes (Kata/Firecracker, gVisor) address multi-tenant isolation where runC cannot.
Kata/Firecracker use KVM + general-purpose Linux guests—higher boot cost and overhead on serverless paths.
Quark and gVisor pair a userspace kernel with a lightweight VMM, targeting fast boot and low RAM while exposing a Linux-ish syscall surface and CRI/OCI so images stay portable. They are less Linux-compatible than Kata-style stacks.
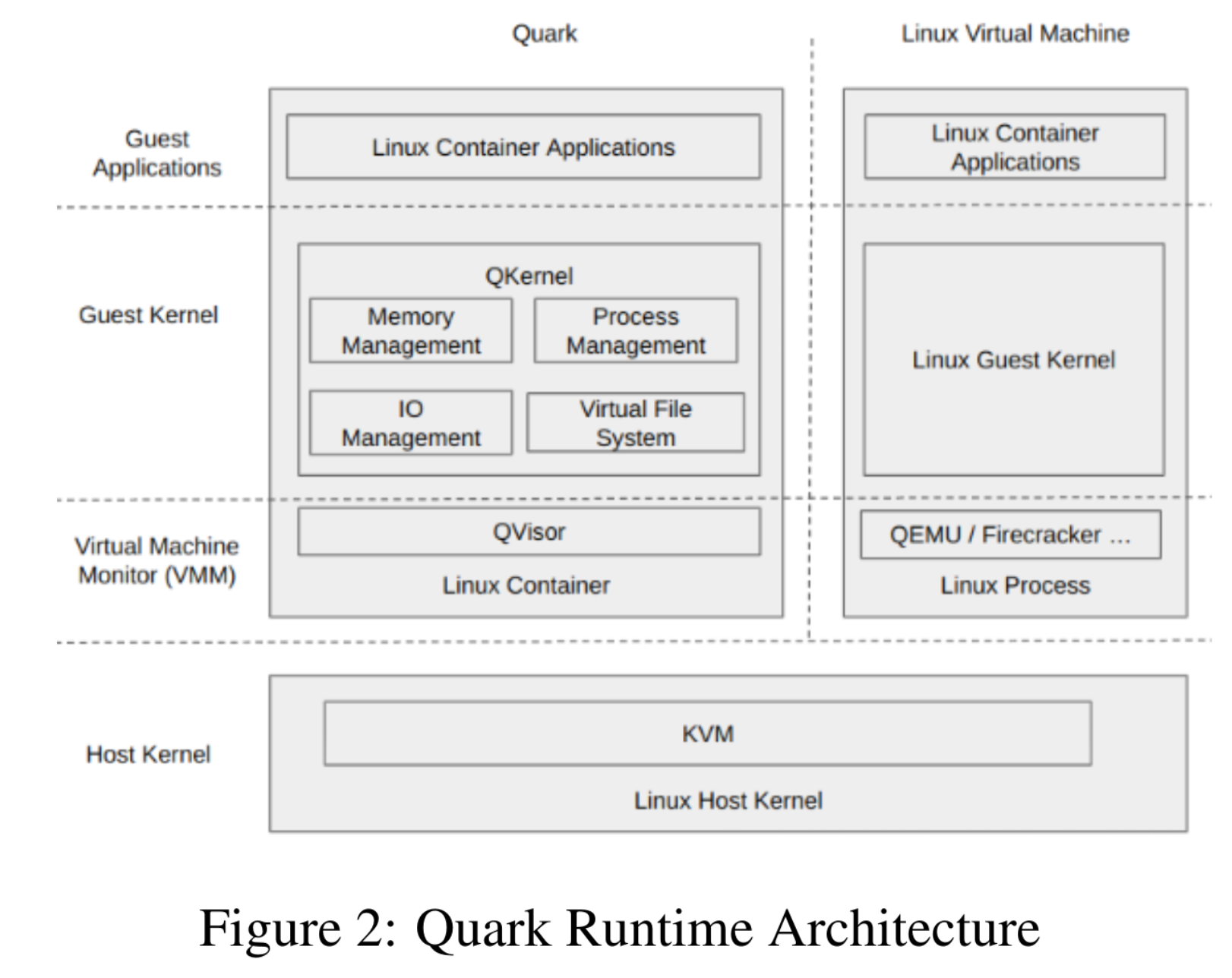
Figure 2 (paper) shows Quark on Linux+KVM: a normal Linux container wraps the Quark process; inside, QKernel + QVisor implement most kernel services (memory, processes, I/O) with serverless-oriented features—including hibernate.
2.2 Returning guest-released memory to the host
Hibernate’s value depends on handing freed guest pages back to the host. General-purpose Linux guests keep freed pages in their own caches instead of returning them—optimized for bare metal, bad for nested/virt. Two classic fixes:
- Ballooning — guest driver cooperates with the hypervisor to resize effective guest RAM.
- Memory plug/unplug — hot-remove regions after migration; costly due to page migration.
Kata/Firecracker guests inherit the problem; balloon/plug are heavy for serverless. Quark adds a dedicated allocator/reclaimer tuned for this environment.
2.3 Swapping guest application memory
Hibernate also swaps active anonymous memory out. Standard host-centric swap in nested setups is inefficient (silent swap writes, stale reads, etc.—VSWAPPER [23]). Serverless offers better swap engineering:
- Batch swap-out of an entire idle container instead of picking cold pages incrementally.
- Race-free swap while the app is paused.
- Sequential batch swap-in — faults cause random SSD reads; REAP [14] shows stable per-invocation working sets that can be prefetched sequentially—cheaper than fault storms.
The paper targets all three opportunities.
3 Design and implementation
3.1 Hibernate state machine
Figure 3 (paper) augments classic hot/cold flows:
- Cold start → new hot container → running while handling a request → returns hot when idle.
- Platforms may keep hot containers briefly for repeat traffic; under memory pressure they evict, forcing the next caller onto the cold path. More hots ⇒ better tail latency when load is there.
New states:
- Hibernate — deflated hot container with lower footprint. Instead of eviction, SIGSTOP can move a hot container into hibernate (deflation).
- Hibernate-running — serves a request while inflating from hibernate.
- Awake — after finishing work, returns from hibernate-running; next request re-enters hibernate-running. SIGSTOP can send an awake container back to hibernate; SIGCONT can pre-wake a hibernate container when the control plane expects traffic, hiding inflation latency.
Awake latency ≈ hot, memory < hot.
3.2 Deflation overview
Four steps from hot → hibernate:
- Pause guest app processes; block host runtime threads waiting for a wake signal.
- Reclaim freed app pages to host Linux.
- Swap dirty anonymous pages to local disk.
madvise(MADV_DONTNEED)on file-backedmmapto return those pages.
Step 1 uses no CPU; steps 2–4 return memory to the host, so footprint drops sharply. Sections 3.3–3.5 detail steps 2–4.
Returning to hot means inflate memory + resume processes. Triggers:
- User request — platform can forward traffic directly; runtime threads block on
accept/readuntil data arrives, then finish swap-in + resume. - Control-plane prefetch — explicit wake before predicted load finishes inflation early, cutting request latency.
3.3 Reclamation-oriented allocation
Like ballooning, hibernate must return freed guest pages to the host. QKernel’s guest physical memory is host virtual memory; unmapped pages aren’t committed until touched. Quark uses madvise(MADV_DONTNEED) to give pages back [24]—after success, anonymous regions fault in as zero-fill on demand.
The stock Quark buddy allocator is poor for this: free blocks chain through next pointers stored inside free memory. After madvise, those pointers zero out and the free list corrupts. Their fix is a bitmap page allocator for user pages allocated on faults.
Two original allocation domains:
- Per-app address space —
brk/mmapcommit virtually; pages fault in later. - Global Rust heap — buddy allocator for kernel structs; old Quark also pulled user pages from this heap on faults, blocking reclamation.
They add (3) the bitmap allocator for 4 KB user pages in the page-fault path.
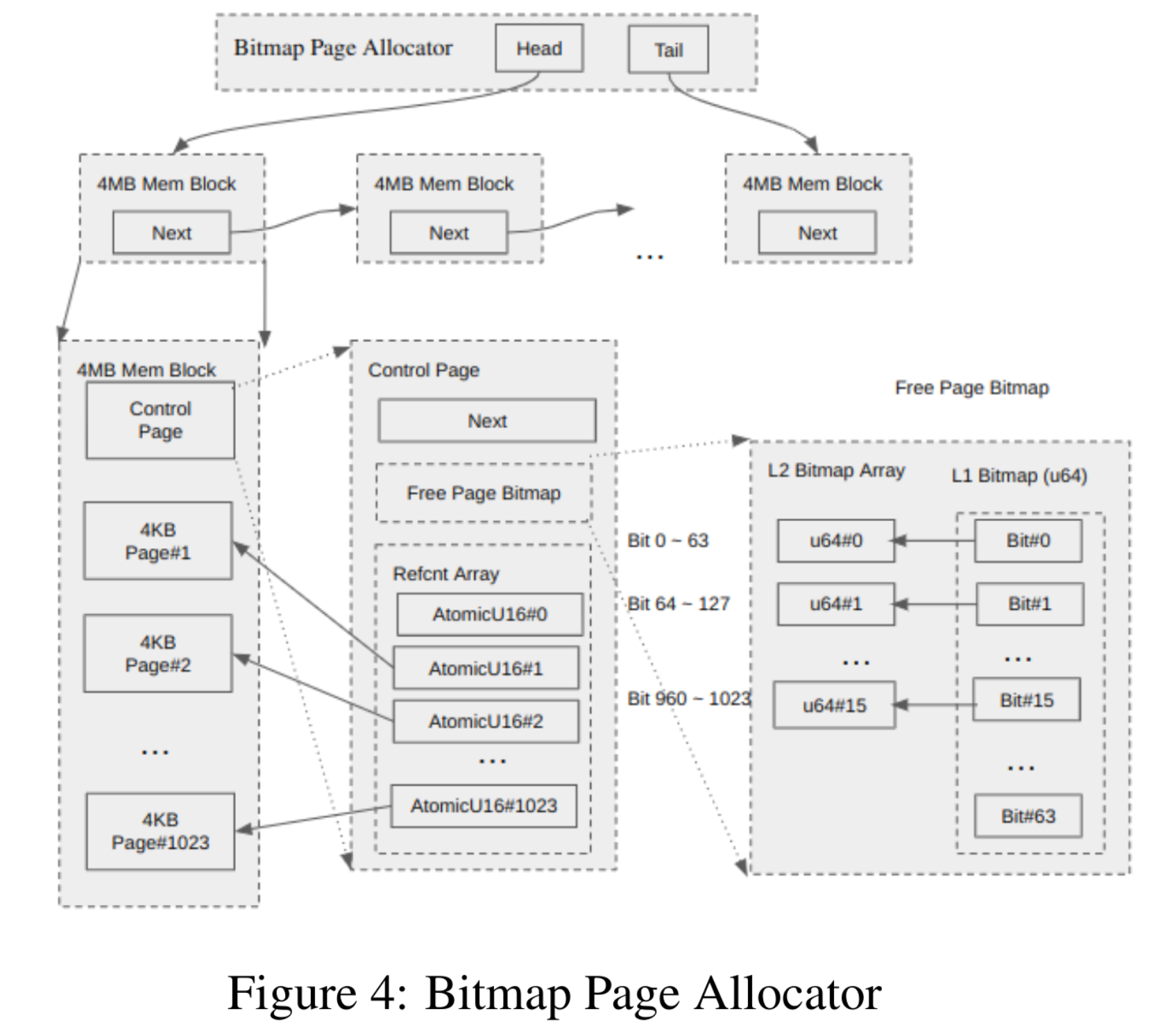
Bitmap allocator (Figure 4) — 4 MB superblocks, 4 MB aligned; first 4 KB page is a control page with:
- Next pointer linking superblocks that still have free pages.
- L2 bitmap — 16×64 bits = 1024 bits covering the 1023 allocatable pages (page 0 is control).
- L1 bitmap — 64-bit mask indicating which L2 words are non-zero → O(1)-ish two-level search (paper states O(2) lookups).
- Per-page 16-bit refcounts in the control page for shared/COW tracking [26].
Allocation pops a page from the first superblock in the list; if exhausted, allocate another superblock from the global buddy under a lock. Refcounts bump on clone/COW; at zero, return the page to the bitmap; if a superblock was empty and now has frees, link it back; if all 1023 slots free, return the superblock to the buddy.
During hibernate, freed data pages contain no buddy metadata—only bitmap bits—so madvise is safe. That’s simpler than ballooning. On wake, the host faults pages back in transparently to QKernel.
3.4 Swapping hibernate memory
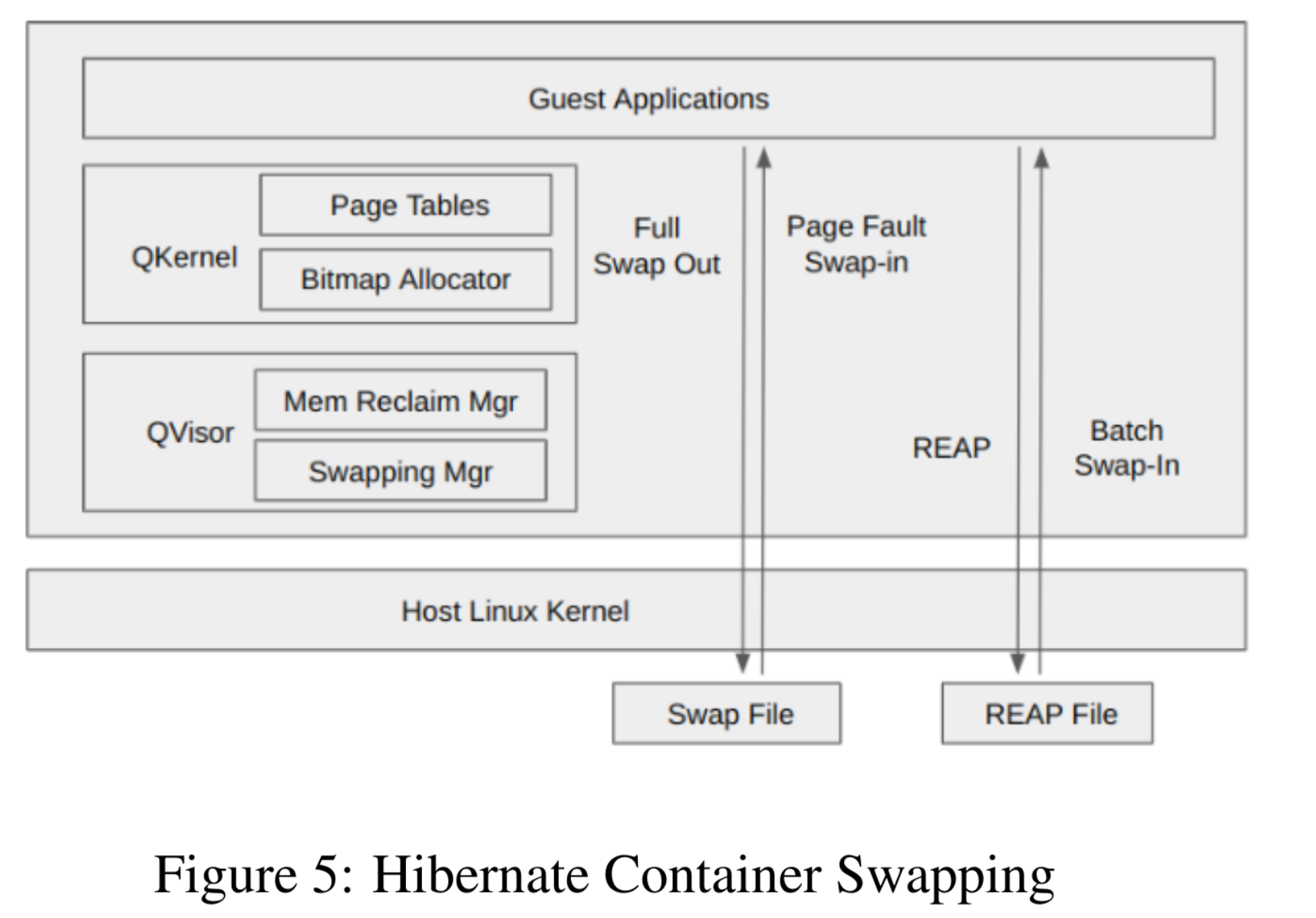
Guest memory swaps to secondary storage; two swap-in modes:
- Demand paging — classic faults load pages.
- REAP batch prefetch — preload pages recorded by REAP.
Each sandbox gets a private swap file (security) plus a REAP file; both deleted when the sandbox dies.
3.4.1 Fault-based swap-out/in
After SIGSTOP, Quark’s swap manager:
- Pause apps — all threads stopped; no races.
- Walk page tables for anonymous pages: mark PTEs not-present, set custom bit #9 (“swapped”), stash guest PAs in a hash for dedupe across shared mappings.
- Write pages to the per-sandbox swap file; record file offsets in the hash.
madvisepages back to the host.
On access, faults check bit #9, exit to host, read 4 KB from the swap file, clear bit #9, mark present.
Costs:
- Full fault path (user→kernel, register save).
- Guest/host mode switches ~15 µs observed.
- Random 4 KB SSD reads ~100 MB/s vs >1 GB/s sequential in their setup.
Empirically only 30–90% of swapped pages are touched per request (e.g. Node hello-world: ~10 MB swapped, ~4 MB faulted in)—initialization pages stay cold. Hence REAP prefetch.
3.4.2 REAP logging + batch swap-in
REAP records the guest physical working set during a probe request, then on the next hibernate writes active anonymous pages sequentially to the REAP file without clearing PTEs (no faults on reinflation). Steps after first hibernate:
- Send a sample request → hibernate-running.
- Record working set while faults pull from the swap file; untouched pages stay in swap.
- Return to awake; SIGSTOP triggers REAP swap-out: pause processes, scan PTEs for active anonymous pages,
pwritevthem into the REAP file from a hashed I/O vector,madviserelease.
Differences vs fault swap-out: PTEs unchanged (no fault on wake), sequential file layout for preadv prefetch.
REAP swap-in:
preadvthe recorded vector sequentially.- Resume the app.
Wins: no fault storms, higher disk throughput.
3.5 File-backed sharing and security
madvise also drops file-backed mmap. Quark can share read-only mappings across containers with COW—skip clearing if still shared to save RAM and boot time.
Multi-tenant risk: shared file caches enable side channels [27]; production guidance discourages aggressive sharing [7]. Two shareable categories:
- Language runtimes (Node, Python) mapped into user space—high cross-tenant risk.
- Runtime binaries (e.g. Kata guest kernel images) not user-mapped—lower risk; RunD shares guest kernels for faster cold start [10].
Hibernate enables sharing for Quark’s own binaries but disables language-runtime sharing by default. Sharing Node’s binary cut hello-world hibernate latency 25 ms → 11 ms in their setup. Mitigations exist [28][29]; Cloudflare Workers trades strict isolation for V8 isolation [29]. Future work could adopt similar mitigations to share more file-backed memory safely.
3.6 Implementation notes
Rust codebase inside Quark (~200k LOC) touches VM, VMM, and I/O paths. New components: swap manager ~780 LOC, bitmap allocator ~484 LOC, reclamation changes ~500 LOC, signal/I/O glue ~300 LOC.
4 Evaluation
Hardware: Intel i7-8700K (12 threads), 64 GB RAM, Samsung PM981 NVMe 512 GB, Ubuntu 20.04, kernel 5.15.0-46.
Workloads:
- Function Bench [30] microbench — float math (small), OpenCV video grayscale (>200 MB, >1 s), Pillow image transforms (two file sizes).
- Language hello-worlds — Python, Node, Go, Java.
4.1 Request latency
Measures HTTP request/response after containers are already provisioned (except cold-start cases). States:
- Cold — boot + first request.
- Hot — steady after init.
- Hibernate (first request after hibernate) — fault vs REAP swap-in.
- Awake — subsequent requests on an awakened container.
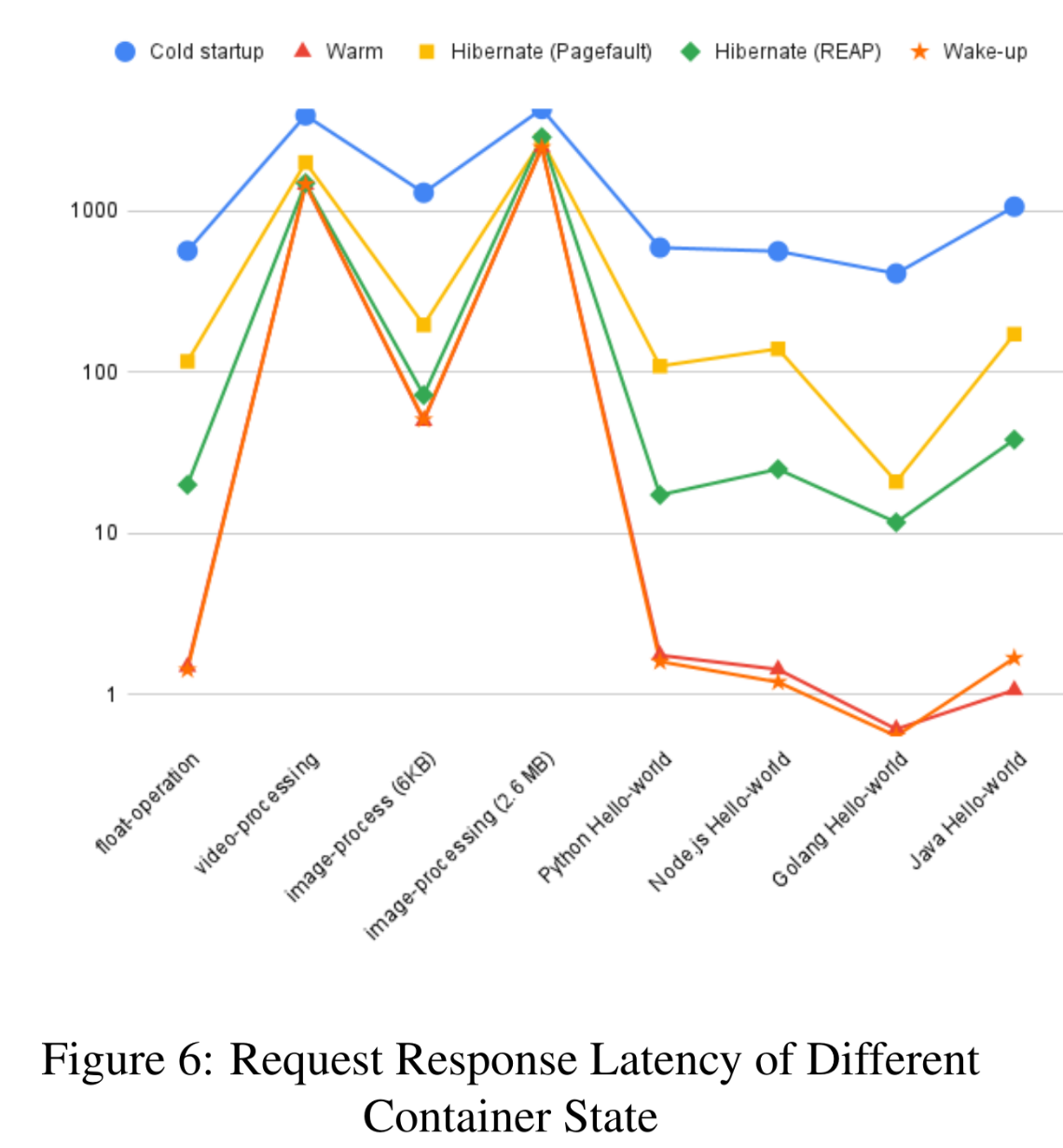
Takeaways (Figure 6):
- Hibernate (especially REAP) ≪ cold — REAP request latency is 3% (Py/Go hello)–67% (2.6 MB image) of cold latency; saves 296 ms–2407 ms cold time depending on bench.
- Awake ≈ hot for request handling.
- Fault-based hibernate slower than REAP on most tests; 2.6 MB image is basically a tie.
4.2 Memory footprint (PSS via pmap)
States: hot (few requests), hibernate (post-deflation), awake (after servicing a request). Hibernate shares Quark binaries, so PSS drops as instances multiply; they report 10 concurrent benchmark instances.
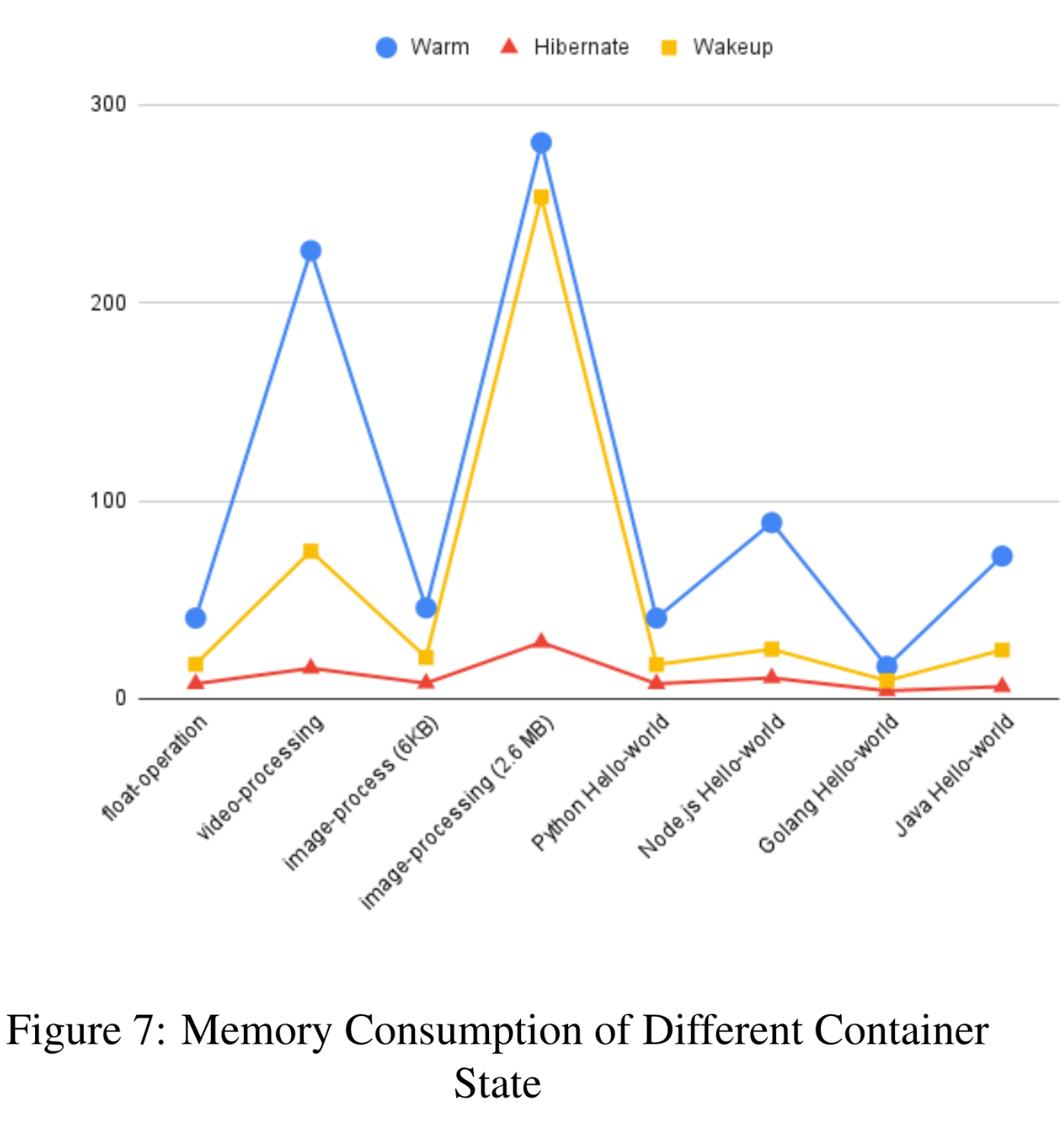
Figure 7:
- Hibernate memory ≈ 7% (video)–25% (Go hello) of hot; saves 12–252 MB depending on workload.
- Awake memory ≈ 28% (Node hello)–90% (2.6 MB image) of hot; saves 7–151 MB.
Together:
- Hibernate + awake clusters beat hot on density.
- Awake keeps hot-like latency with lower RAM—worth converting hots to hibernate/awake when possible.
5 Related work
Cold start = secure runtime boot + app start.
5.1 VM-based runtime optimizations
Includes cgroup/net/fs setup + guest kernel boot. RunD [10] pre-creates cgroups, optimizes rootfs mapping, uses Kata templates to cut per-microVM memory/latency. Firecracker [19] trims devices (virtio-net + single block type) for serverless. Quark [18] / gVisor [8] replace the guest kernel with userspace kernels + slim VMMs.
5.2 Application start optimizations
Move starts “closer” to hot: checkpoint/restore on gVisor or JVM [13][31]; reuse dying hots for new images [32]. Catalyzer [13] does initialization-free boot atop C/R; REAP batches prefetch during VMM image load; Sock [12] forks zygote-like helpers with pre-imported packages; sfork forks full app state from a hot parent with shared memory.
Conclusion
Low-latency starts define serverless UX. Beyond pure cold and pure hot, hibernate containers offer a third mode: deflated hots. Experiments show much lower memory than hot, lower latency than cold, and awake containers that track hot latency with smaller footprints—boosting density and overall performance.