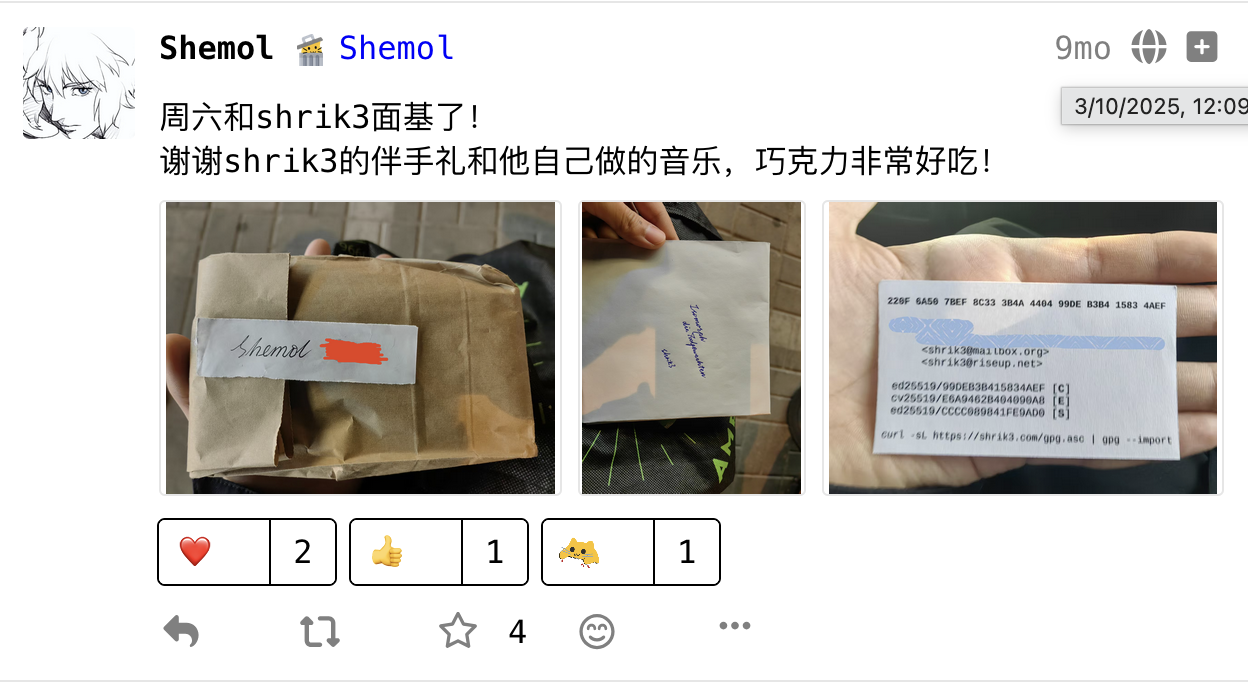
KubeEdge-Sedna ソースコード解析(転載)
原著者:jaypume
公開講義動画:https://www.bilibili.com/video/BV1hg4y1b78L
原著 README:https://github.com/jaypume/article/blob/main/sedna/边云协同AI框架Sedna源码解析/README.MD
学習・参照のため転載。
KubeEdge-Sedna 概要
Sedna は KubeEdge SIG AI で育てられてきたクラウド–エッジ協調 AI プロジェクトである。KubeEdge の協調能力により、連合推論・増分学習・連邦学習・ライフロング学習など、クラウドとエッジにまたがる学習・推論が可能になる。TensorFlow/PyTorch/MindSpore など主要フレームワークを想定しており、既存アプリを比較的スムーズに載せ替え、コスト・モデル性能・データプライバシー面での利点を狙える。
プロジェクト:
https://github.com/kubeedge/sedna
ドキュメント:
https://sedna.readthedocs.io
全体アーキテクチャ
Sedna の協調は KubeEdge の次の能力の上に乗る。
* クラウド–エッジ横断のアプリ統合オーケストレーション
* Router:管理面の高信頼メッセージ経路
* EdgeMesh:データ面のサービス発見とトラフィック制御
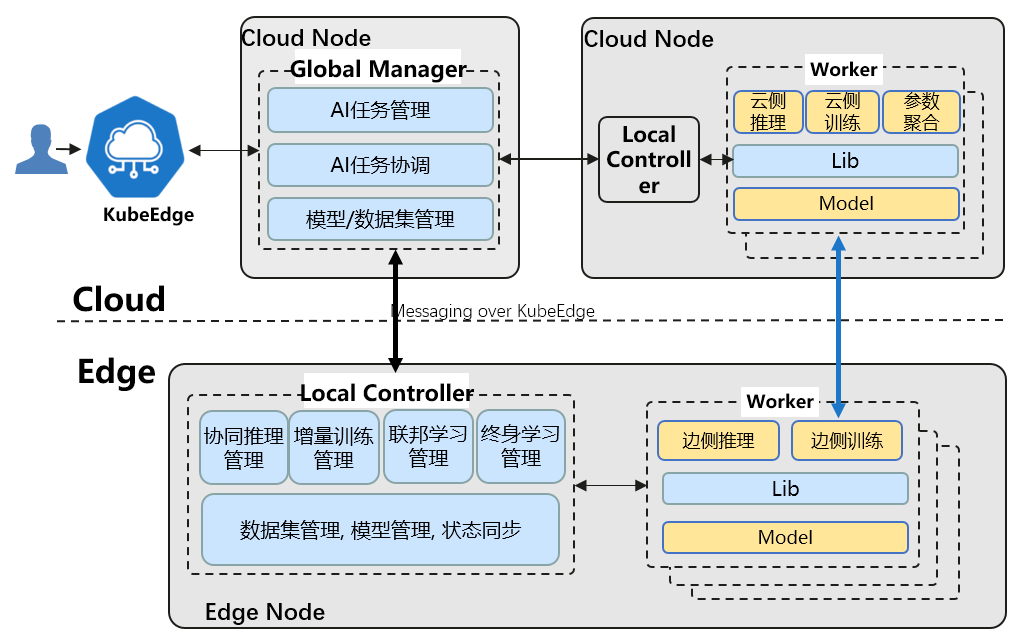 主なコンポーネント:
GlobalManager
主なコンポーネント:
GlobalManager
- 協調 AI ジョブの一元管理
- クラウド–エッジ間の調整
- 中央設定
LocalController
- エッジ側のローカル制御
- モデル・データセット・状態同期などのローカル管理
Lib
- AI/アプリ開発者向けに協調機能を API として提供
Worker
- 学習・推論の実行(既存フレームワーク上のプログラム)
- 機能ごとにワーカー群があり、エッジ/クラウドに配置して協調
リポジトリ構成
| ディレクトリ | 内容 |
| --- | --- |
| .github | GitHub CI/CD 設定 |
| LICENSES | Sedna および vendor のライセンス |
| build | GM/LC 等の Dockerfile、生成 CRD YAML、サンプル CR |
| cmd | GM/LC のエントリ |
| components | 監視・可視化など |
| docs | proposal とインストール手順 |
| examples | 連合推論・増分・ライフロング・連邦学習の例 |
| hack | コード生成ツールや開発用スクリプト |
| lib | Python ライブラリ(協調 AI アプリ開発用) |
| pkg | API 定義、client-go 生成コード、GM/LC の中核 |
| scripts | 利用者向けインストールスクリプト |
| test | E2E とテストユーティリティ |
| vendor | サードパーティソース |
Sedna 管理面ソース(Go)
GM: Global Manager
GM は一種の Kubernetes Operator
Operator とは?
An Operator is an application-specific controller that extends the Kubernetes API to create, configure and manage instances of complex stateful applications on behalf of a Kubernetes user. It builds upon the basic Kubernetes resource and controller concepts, but also includes domain or application-specific knowledge to automate common tasks better managed by computers. 1
Sedna の GM は、協調 AI アプリにおけるワーカーのデプロイ・起動パラメータ、協調の仕方、データの流れなどを司る。「クラウド–エッジ協調 AI アプリ」というドメイン特化のコントローラと言える。
The following components form the three main parts of an operator:
- API: The data that describes the operand’s configuration. The API includes:
- Custom resource definition (CRD), which defines a schema of settings available for configuring the operand.
- Programmatic API, which defines the same data schema as the CRD and is implemented using the operator’s programming language, such as Go.
- Custom resource (CR), which specifies values for the settings defined by the CRD; these values describe the configuration of an operand.
- Controller: The brains of the operator. The controller creates managed resources based on the description in the custom resource; controllers are implemented using the operator’s programming language, such as Go. 2
Red Hat の定義によれば、Kubernetes Operator を構成する主な概念は CRD、API、CR、Controller である。
Sedna GM を Operator として見たときの模式図:
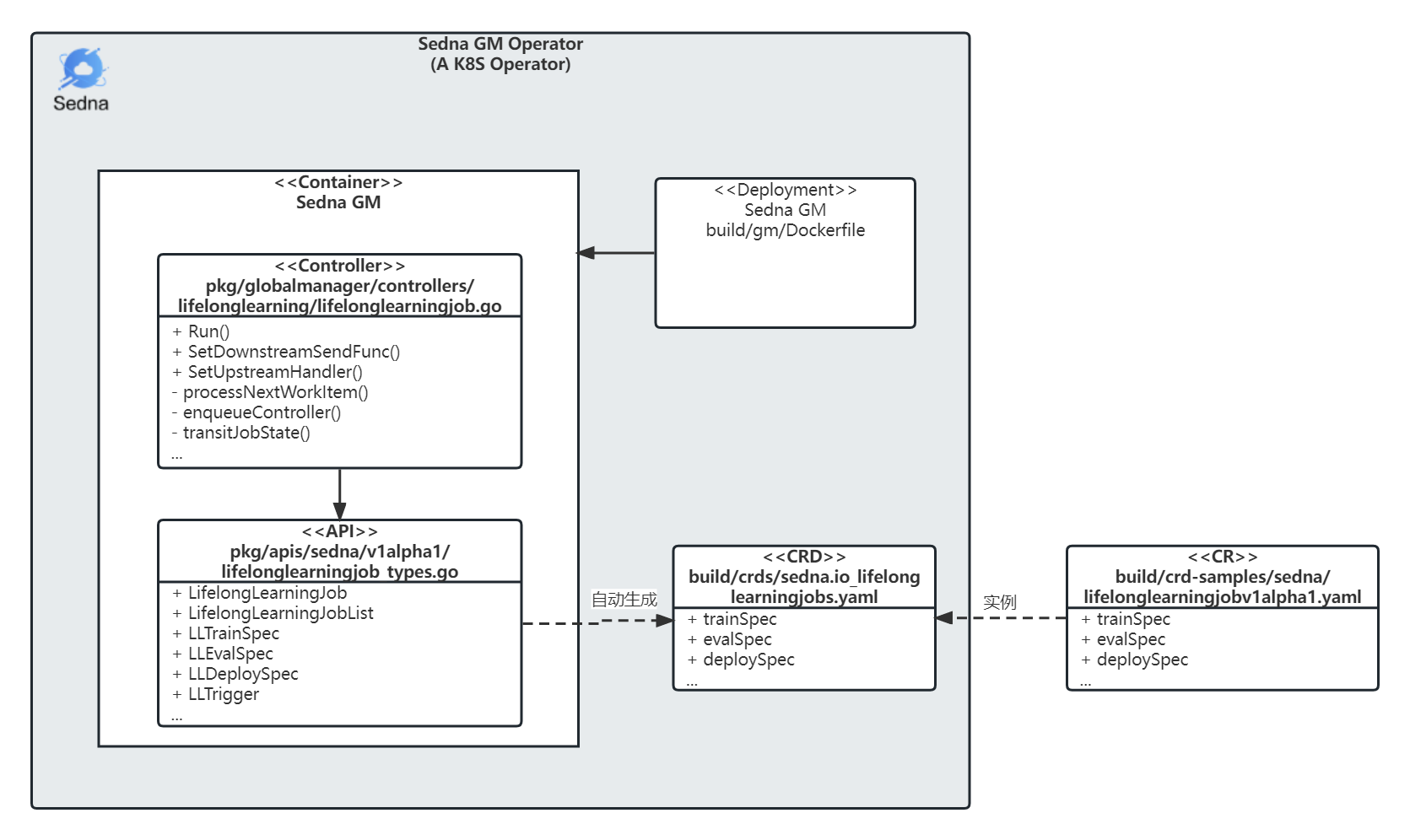
以降は CR、CRD、API、Controller の順に触れる。制御の本体は Controller。
CR
Sedna は連合推論・増分学習・ライフロング学習・連邦学習をサポートする。コード読みやすさのため本稿はライフロング学習の特性とサンプルに寄せて説明する。他三つも実装パターンは共通部分が多い。
CR サンプル
ライフロング学習の CR サンプル を引用する。これを kubectl で適用してリソースを作れる。手順の詳細は examples/lifelong_learning/atcii。主要フィールド:
dataset:データセット CR の名前(データセットも CR)。
trainSpec:学習ワーカーの Pod テンプレート(イメージ・環境変数など)。
trigger:学習ワーカーを起こす条件。
evalSpec:評価ワーカーのテンプレート。
deploySpec:推論ワーカーのテンプレート。
outputDir:学習で出力するモデルパス。
build/crd-samples/sedna/lifelonglearningjobv1alpha1.yaml
``yaml
apiVersion: sedna.io/v1alpha1
kind: LifelongLearningJob
metadata:
name: atcii-classifier-demo
spec:
dataset:
name: "lifelong-dataset"
trainProb: 0.8
trainSpec:
template:
spec:
nodeName: "edge-node"
containers:
- image: kubeedge/sedna-example-lifelong-learning-atcii-classifier:v0.3.0
name: train-worker
imagePullPolicy: IfNotPresent
args: ["train.py"]
env:
- name: "early_stopping_rounds"
value: "100"
- name: "metric_name"
value: "mlogloss"
trigger:
checkPeriodSeconds: 60
timer:
start: 02:00
end: 24:00
condition:
operator: ">"
threshold: 500
metric: num_of_samples
evalSpec:
template:
spec:
nodeName: "edge-node"
containers:
- image: kubeedge/sedna-example-lifelong-learning-atcii-classifier:v0.3.0
name: eval-worker
imagePullPolicy: IfNotPresent
args: ["eval.py"]
env:
- name: "metrics"
value: "precision_score"
- name: "metric_param"
value: "{'average': 'micro'}"
- name: "model_threshold"
value: "0.5"
deploySpec:
template:
spec:
nodeName: "edge-node"
containers:
- image: kubeedge/sedna-example-lifelong-learning-atcii-classifier:v0.3.0
name: infer-worker
imagePullPolicy: IfNotPresent
args: ["inference.py"]
env:
- name: "UT_SAVED_URL"
value: "/ut_saved_url"
- name: "infer_dataset_url"
value: "/data/testData.csv"
volumeMounts:
- name: utdir
mountPath: /ut_saved_url
- name: inferdata
mountPath: /data/
resources:
limits:
memory: 2Gi
volumes:
- name: utdir
hostPath:
path: /lifelong/unseen_task/
type: DirectoryOrCreate
- name: inferdata
hostPath:
path: /data/
type: DirectoryOrCreate
outputDir: "/output"
`
CRD
CRD は CR の雛形である。CR を作る前にクラスタへ CRD を登録する必要がある。YAML は手書きでもよいが、複雑ならツール生成が無難。Sedna は kubebuilder の controller-gen で CRD を生成・更新し、
make crds で build/crds/ を更新する(Makefile の crds: controller-gen を参照)。
CRD では group・version・kind(GVK)が肝になる。CR インスタンスは Resource と呼ばれ、OO で言えば Kind がクラス、Resource がオブジェクトに近い。ライフロング学習の GVR/GVK は次表。
| | Group | Version | Resource | Kind |
| --- | --- | --- | --- | --- |
| CRD | apiextensions.k8s.io | v1 | lifelonglearningjobs.sedna.io | CustomResourceDefinition |
| CR | sedna.io | v1alpha1 | lifelonglearningjob | LifelongLearningJob |
クラスタ内のリソースは REST URI で表される。パスの組み立ては次図のとおり。

規則が分かれば、管理対象の REST URL を手で組み立てられる。公式 client がない言語でも HTTP で叩ける。例:
ライフロング学習 CRD の取得:
`plain text
curl -k --cert ./client.crt --key ./client.key https://127.0.0.1:5443/apis/apiextensions.k8s.io/v1beta1/customresourcedefinitions/lifelonglearningjobs.sedna.io
`
ライフロング学習 CR 一覧:
`plain text
curl -k --cert ./client.crt --key ./client.key https://127.0.0.1:5443/apis/sedna.io/v1alpha1/lifelonglearningjobs
`
Sedna のライフロング学習 CRD で注目すべきフィールド:
apiVersion: apiextensions.k8s.io/v1 — 現行 CRD はこの API グループ。
kind: CustomResourceDefinition
spec.group: sedna.io
spec.names.kind: LifelongLearningJob
spec.names.shortNames: - ll — kubectl get ll などの短縮名。
build/crds/sedna.io_lifelonglearningjobs.yaml
`yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
annotations:
controller-gen.kubebuilder.io/version: v0.4.1
creationTimestamp: null
name: lifelonglearningjobs.sedna.io
spec:
group: sedna.io
names:
kind: LifelongLearningJob
listKind: LifelongLearningJobList
plural: lifelonglearningjobs
shortNames:
- ll
singular: lifelonglearningjob
scope: Namespaced
versions:
- name: v1alpha1
...
status:
acceptedNames:
kind: ""
plural: ""
conditions: []
storedVersions: []
`
API
CRD を自動生成するための型定義は次にある。
pkg/apis/sedna/v1alpha1/lifelonglearningjob_types.go
`go
package v1alpha1
import (
v1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
// 这里展示了
// +genclient
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// +kubebuilder:resource:shortName=ll
// +kubebuilder:subresource:status
// 整体的LifelongLearningJob的API定义,主要包含Spec和Status定义,分别代表期望状态和实际状态。
type LifelongLearningJob struct {
metav1.TypeMeta
json:",inline"
metav1.ObjectMeta
json:"metadata"
Spec LLJobSpec
json:"spec"
Status LLJobStatus
json:"status,omitempty"
}
// 在创建LifelongLearningJob时候需要配置的参数;如果需要扩展终身学习字段的接口,可以在这里修改。
type LLJobSpec struct {
Dataset LLDataset
json:"dataset"
TrainSpec LLTrainSpec
json:"trainSpec"
EvalSpec LLEvalSpec
json:"evalSpec"
DeploySpec LLDeploySpec
json:"deploySpec"
// the credential referer for OutputDir
CredentialName string
json:"credentialName,omitempty"
OutputDir string
json:"outputDir"
}
type LLDataset struct {
Name string
json:"name"
TrainProb float64
json:"trainProb"
}
// 剩下还有一些结构体定义省略了。
`
補足:
// +kubebuilder... はコード生成ツール向けのディレクティブ。
LifelongLearningJob が Spec(望ましい状態)と Status(実状態)を持つ API の核。
LLJobSpec は CR 作成時にユーザーが埋めるフィールド。拡張もここから。
連合推論・増分・連邦学習の型は同じく
pkg/apis/sedna/v1alpha1/ 以下。
client-go の再生成
*_types.go を変えたら次を実行:
`plain text
bash hack/update-codegen.sh
`
生成物は
pkg/client:
`plain text
➜ pkg tree client -L 2
client
├── clientset
│ └── versioned
├── informers
│ └── externalversions
└── listers
└── sedna
`
後述の Controller から参照される。
CRD YAML の更新
同様に型を変えたら:
`plain text
make crds
`
出力先は
build/crds。クラスタ側も kubectl apply で CRD を更新する。
Controller
ライフロング学習の中核は
pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go(学習/評価ワーカーの起動タイミング、エッジへのパラメータ同期など)。
全体の呼び出しは次の疑似コードで把握できる:
`go
cmd/sedna-gm/sedna-gm.go/main() 【1】
pkg/globalmanager/controllers/manager.go/New() 【2】GM 設定読み込み
pkg/globalmanager/controllers/manager.go/Start() 【3】GM プロセス起動
- clientset.NewForConfig():【4】client-go で Sedna CRD 用 clientset 生成
- NewUpstreamController():【5】UpstreamController 生成(GM プロセスあたり 1 つ)
- uc.Run(stopCh):for ループの goroutine で
- pkg/globalmanager/controllers/upstream.go/syncEdgeUpdate()
- NewRegistry():【6】全 controller 登録
- f.SetDownstreamSendFunc()【7】
-> pkg/globalmanager/controllers/lifelonglearning/downstream.go
- f.SetUpstreamHandler()【8】
-> pkg/globalmanager/controllers/lifelonglearning/upstream.go/updateFromEdge()
- f.Run()【9】
- ws.ListenAndServe() 【10】
`
LifelongLearningJob Controller の説明も、上記【1】〜【10】に沿う。
【1】
main エントリ
sedna-gm.go は GM の入口。ログ初期化、app.NewControllerCommand() でフラグ解析と controller 起動。
cmd/sedna-gm/sedna-gm.go
`go
func main() {
rand.Seed(time.Now().UnixNano())
command := app.NewControllerCommand()
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
`
【2】GM 設定の読み込み
k8s 接続情報、WebSocket の待受アドレス/ポート、ナレッジベース(KB)URL などを読み込む。
pkg/globalmanager/controllers/manager.go
`go
// New creates the controller manager
func New(cc config.ControllerConfig) Manager {
config.InitConfigure(cc)
return &Manager{
Config: cc,
}
}
`
pkg/globalmanager/config/config.go
`go
// ControllerConfig indicates the config of controller
type ControllerConfig struct {
// KubeAPIConfig indicates the kubernetes cluster info which controller will connected
KubeConfig string
json:"kubeConfig,omitempty"
// Master indicates the address of the Kubernetes API server. Overrides any value in KubeConfig.
// such as https://127.0.0.1:8443
// default ""
Master string
json:"master"
// Namespace indicates which namespace the controller listening to.
// default ""
Namespace string
json:"namespace,omitempty"
// websocket server config
// Since the current limit of kubeedge(1.5), GM needs to build the websocket channel for communicating between GM and LCs.
WebSocket WebSocket
json:"websocket,omitempty"
// lc config to info the worker
LC LCConfig
json:"localController,omitempty"
// kb config to info the worker
KB KBConfig
json:"knowledgeBaseServer,omitempty"
// period config min resync period
// default 30s
MinResyncPeriodSeconds int64
json:"minResyncPeriodSeconds,omitempty"
}
`
【3】GM の全体初期化
Sedna CRD 用クライアント作成、クラウド–エッジメッセージ処理のバインド、機能別 controller の起動、WebSocket 待受開始、までをまとめて行う。
pkg/globalmanager/controllers/manager.go
`go
// Start starts the controllers it has managed
func (m *Manager) Start() error {
...
// 初始化Sedna CRD client,Controller会监听Sedna CR 增删改查的变化,并执行对应的处理逻辑。
sednaClient, err := clientset.NewForConfig(kubecfg)
...
sednaInformerFactory := sednainformers.NewSharedInformerFactoryWithOptions(sednaClient, genResyncPeriod(minResyncPeriod), sednainformers.WithNamespace(namespace))
// 初始化UpstreamController,用于处理边缘LC上传的消息
uc, _ := NewUpstreamController(context)
downstreamSendFunc := messagelayer.NewContextMessageLayer().SendResourceObject
stopCh := make(chan struct{})
go uc.Run(stopCh)
// 针对每个特性(协同推理、终身学习等),绑定对应的消息处理函数
for name, factory := range NewRegistry() {
...
f.SetDownstreamSendFunc(downstreamSendFunc)
f.SetUpstreamHandler(uc.Add)
...
// 启动各个特性对应controller
go f.Run(stopCh)
}
...
// 启动整体GM的websocket,默认监听在0.0.0.0:9000这个端口地址
ws := websocket.NewServer(addr)
...
}
`
【4】CRD クライアント初期化
clientset.NewForConfig() の実体は pkg/client/clientset/versioned/clientset.go。codegen 済みの clientset で CR の CRUD を行う。
LifelongLearningJob Controller の New は主に次を行う:
LifelongLearningJob の Informer 取得(API Server 負荷軽減のローカルキャッシュ)
kube/sedna クライアントや GM 共通設定の注入
Job CR の Add/Update/Delete にコールバックを登録
pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go
`go
// New creates a new LifelongLearningJob controller that keeps the relevant pods
// in sync with their corresponding LifelongLearningJob objects.
func New(cc *runtime.ControllerContext) (runtime.FeatureControllerI, error) {
cfg := cc.Config
podInformer := cc.KubeInformerFactory.Core().V1().Pods()
// 获取LifelongLearningJob的Informer
jobInformer := cc.SednaInformerFactory.Sedna().V1alpha1().LifelongLearningJobs()
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: cc.KubeClient.CoreV1().Events("")})
// 配置LifelongLearningJob Controller的参数
jc := &Controller{
kubeClient: cc.KubeClient,
client: cc.SednaClient.SednaV1alpha1(),
queue: workqueue.NewNamedRateLimitingQueue(workqueue.NewItemExponentialFailureRateLimiter(runtime.DefaultBackOff, runtime.MaxBackOff), Name),
cfg: cfg,
}
// 绑定LifelongLearningJob CRD资源的Add、Update、Delete对应事件的回调函数。
jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jc.enqueueController(obj, true)
jc.syncToEdge(watch.Added, obj)
},
UpdateFunc: func(old, cur interface{}) {
jc.enqueueController(cur, true)
jc.syncToEdge(watch.Added, cur)
},
DeleteFunc: func(obj interface{}) {
jc.enqueueController(obj, true)
jc.syncToEdge(watch.Deleted, obj)
},
})
jc.jobLister = jobInformer.Lister()
jc.jobStoreSynced = jobInformer.Informer().HasSynced
// 绑定Pod对应的增删改对应事件的回调函数。
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: jc.addPod,
UpdateFunc: jc.updatePod,
DeleteFunc: jc.deletePod,
})
jc.podStore = podInformer.Lister()
jc.podStoreSynced = podInformer.Informer().HasSynced
return jc, nil
}
`
図は他モジュールから Sedna clientset を参照している例。
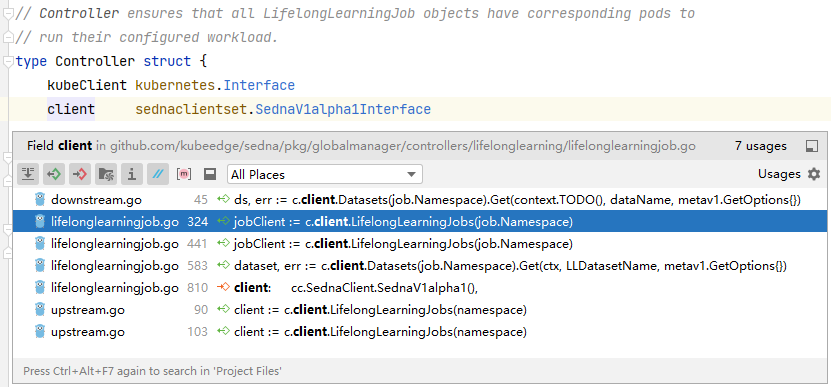
【5】アップストリーム(エッジ→クラウド)の初期化
uc.Run() が UpstreamController を回し、エッジ LC からの更新をまとめて処理する。
ループでメッセージレイヤから受け取り、
uc.updateHandlers[kind] で連合推論・増分・連邦・ライフロングなど種別ごとのハンドラに振る。
pkg/globalmanager/controllers/upstream.go
`go
// syncEdgeUpdate receives the updates from edge and syncs these to k8s.
func (uc *UpstreamController) syncEdgeUpdate() {
for {
select {
case <-uc.messageLayer.Done():
klog.Info("Stop sedna upstream loop")
return
default:
}
update, err := uc.messageLayer.ReceiveResourceUpdate()
...
handler, ok := uc.updateHandlers[kind]
if ok {
err := handler(name, namespace, operation, update.Content)
...
}
}
}
`
ReceiveFromEdge は LC からのメッセージをブロッキングで受ける経路(実装はレイヤ内で nodeMessage 等として扱う)。
pkg/globalmanager/messagelayer/ws/context.go
`go
// ReceiveResourceUpdate receives and handles the update
func (cml ContextMessageLayer) ReceiveResourceUpdate() (ResourceUpdateSpec, error) {
nodeName, msg, err := wsContext.ReceiveFromEdge()
...
}
`
【6】Controller の登録
NewRegistry() が機能ごとの New を束ねる。新しい協調機能を足すならここにエントリを追加する。
pkg/globalmanager/controllers/registry.go
`go
func NewRegistry() Registry {
return Registry{
ji.Name: ji.New,
fe.Name: fe.New,
fl.Name: fl.New,
il.Name: il.New,
ll.Name: ll.New,
reid.Name: reid.New,
va.Name: va.New,
dataset.Name: dataset.New,
objs.Name: objs.New,
}
}
`
【7】クラウド→エッジの同期
f.SetDownstreamSendFunc() が各機能の syncToEdge を下流送信に結び付ける。
ライフロング学習では概ね次の順:
Dataset CR からデータ所在ノードを取得
Annotation から学習/評価/デプロイ各フェーズのノード名を取得
現在フェーズに応じてメッセージを送る先を切り替える
pkg/globalmanager/controllers/lifelonglearning/downstream.go
`go
func (c *Controller) syncToEdge(eventType watch.EventType, obj interface{}) error {
// 获取到对应的数据集指定的节点(Dataset CRD对象中有一个字段记录了Node名称)
ds, err := c.client.Datasets(job.Namespace).Get(context.TODO(), dataName, metav1.GetOptions{})
// 获取到训练、评估、部署对应的节点名称
getAnnotationsNodeName := func(nodeName sednav1.LLJobStage) string {
return runtime.AnnotationsKeyPrefix + string(nodeName)
}
ann := job.GetAnnotations()
if ann != nil {
trainNodeName = ann[getAnnotationsNodeName(sednav1.LLJobTrain)]
evalNodeName = ann[getAnnotationsNodeName(sednav1.LLJobEval)]
deployNodeName = ann[getAnnotationsNodeName(sednav1.LLJobDeploy)]
}
...
// 根据LifelongLearningJob所处阶段不同,发送消息到不同的节点上
switch jobStage {
case sednav1.LLJobTrain:
doJobStageEvent(trainNodeName)
case sednav1.LLJobEval:
doJobStageEvent(evalNodeName)
case sednav1.LLJobDeploy:
doJobStageEvent(deployNodeName)
}
return nil
}
`
【8】エッジ→クラウドの同期
f.SetUpstreamHandler() が updateFromEdge を登録する。
ライフロング学習では:
LC からの報告に応じてジョブ全体の状態を更新
LifelongLearningJob の Status を k8s に書き戻す
JSON 本文をパースする。GM が受け取る例:
`json
{
"phase": "train",
"status": "completed",
"output": {
"models": [{
"classes": ["road", "fence"],
"current_metric": null,
"format": "pkl",
"metrics": null,
"url": "/output/train/1/index.pkl"
}],
"ownerInfo": null
}
}
`
pkg/globalmanager/controllers/lifelonglearning/upstream.go
`go
// updateFromEdge syncs the edge updates to k8s
func (c *Controller) updateFromEdge(name, namespace, operation string, content []byte) error {
var jobStatus struct {
Phase string
json:"phase"
Status string
json:"status"
}
// 把边缘消息结构体进行解析。
err := json.Unmarshal(content, &jobStatus)
...
cond := sednav1.LLJobCondition{
Status: v1.ConditionTrue,
LastHeartbeatTime: metav1.Now(),
LastTransitionTime: metav1.Now(),
Data: string(condDataBytes),
Message: "reported by lc",
}
// 根据不同的边缘节点任务状态实现,变更当前LifelongLearningJob的整体状态
switch strings.ToLower(jobStatus.Status) {
case "ready":
cond.Type = sednav1.LLJobStageCondReady
case "completed":
cond.Type = sednav1.LLJobStageCondCompleted
case "failed":
cond.Type = sednav1.LLJobStageCondFailed
case "waiting":
cond.Type = sednav1.LLJobStageCondWaiting
default:
return fmt.Errorf("invalid condition type: %v", jobStatus.Status)
}
// 将当前LifelongLearningJob的整体状态写回k8s,也就是LifelongLearningJob这个CR的Status字段。
err = c.appendStatusCondition(name, namespace, cond)
...
}
`
【9】Controller のメイン処理
各機能の
Run がワーカーを起動する。ライフロングでは WaitForNamedCacheSync で Pod/Job の Informer 同期を待ってから worker を回す。
pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go
`go
// Run starts the main goroutine responsible for watching and syncing jobs.
func (c *Controller) Run(stopCh <-chan struct{}) {
workers := 1
defer utilruntime.HandleCrash()
defer c.queue.ShutDown()
klog.Infof("Starting %s controller", Name)
defer klog.Infof("Shutting down %s controller", Name)
if !cache.WaitForNamedCacheSync(Name, stopCh, c.podStoreSynced, c.jobStoreSynced) {
klog.Errorf("failed to wait for %s caches to sync", Name)
return
}
klog.Infof("Starting %s workers", Name)
for i := 0; i < workers; i++ {
go wait.Until(c.worker, time.Second, stopCh)
}
<-stopCh
}
`
worker は processNextWorkItem を回し、キューから key を取り出して sync に渡す。
pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go
`go
// worker runs a worker thread that just dequeues items, processes them, and marks them done.
// It enforces that the syncHandler is never invoked concurrently with the same key.
func (c *Controller) worker() {
for c.processNextWorkItem() {
}
}
`
続けて
sync の本体。
pkg/globalmanager/controllers/lifelonglearning/lifelonglearningjob.go
`go
func (c *Controller) sync(key string) (bool, error) {
//省略了部分代码
ns, name, err := cache.SplitMetaNamespaceKey(key)
sharedJob, err := c.jobLister.LifelongLearningJobs(ns).Get(name)
// if job was finished previously, we don't want to redo the termination
if IsJobFinished(&job) {
return true, nil
}
// transit this job's state machine
needUpdated, err = c.transitJobState(&job)
if needUpdated {
if err := c.updateJobStatus(&job); err != nil {
return forget, err
}
if jobFailed && !IsJobFinished(&job) {
// returning an error will re-enqueue LifelongLearningJob after the backoff period
return forget, fmt.Errorf("failed pod(s) detected for lifelonglearningjob key %q", key)
}
forget = true
}
return forget, err
}
`
sync は個別ジョブの状態機械を進める:
key を namespace/name に分割
lister で LifelongLearningJob を取得
transitJobState で学習→評価→デプロイなどへ遷移すべきか判断
変化があれば updateJobStatus で API に反映(kubectl で見える最新フェーズやモデルパスなど)
失敗時の再キュー/エラー処理
`go
// transit this job's state machine
needUpdated, err = c.transitJobState(&job)
`
transitJobState() がフェーズ遷移の中核。詳細は次の状態図と照らすとよい。
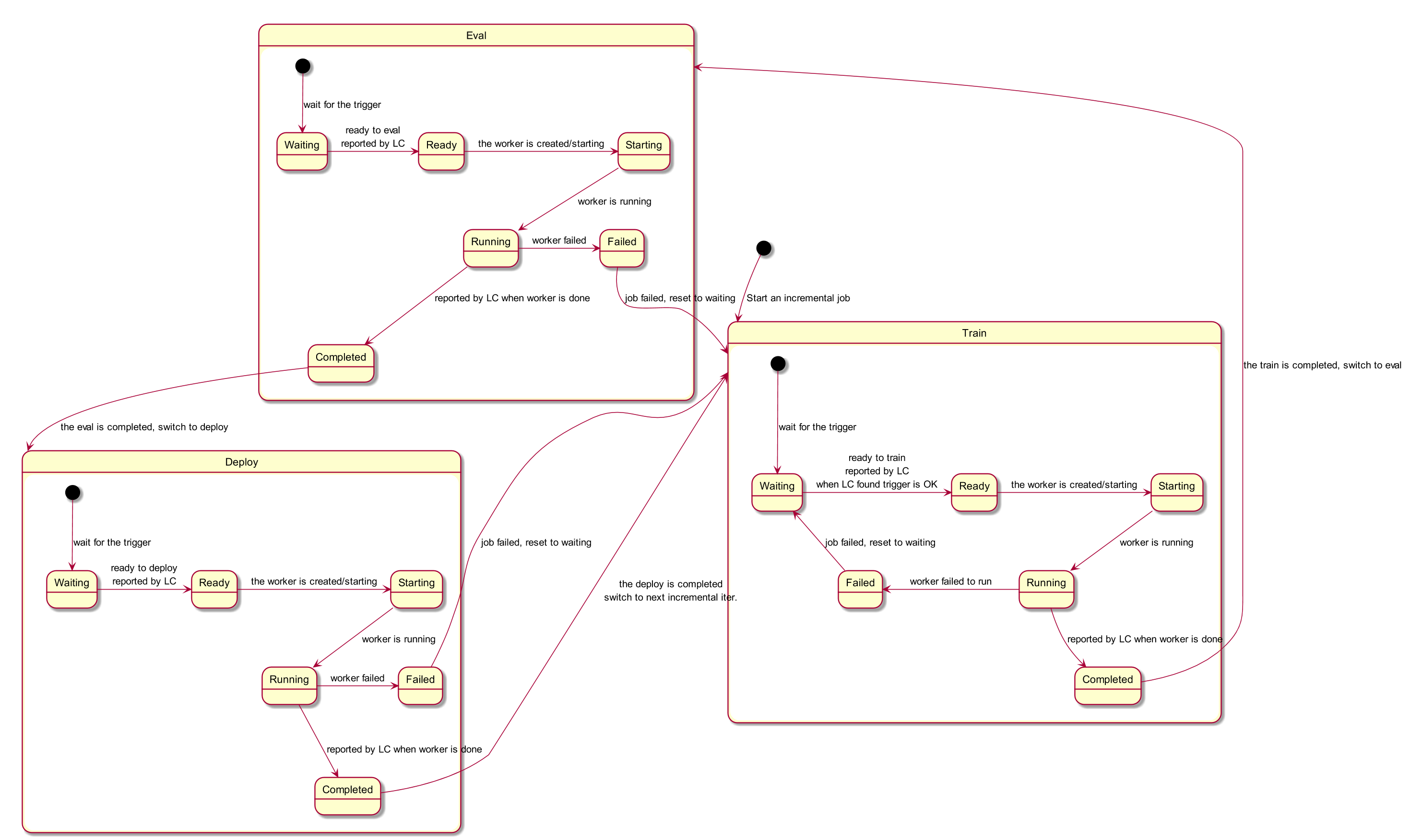
【10】WebSocket サーバ起動
【8】の LC からのメッセージを受ける WebSocket。デフォルトは
0.0.0.0:9000。
pkg/globalmanager/controllers/manager.go
`go
addr := fmt.Sprintf("%s:%d", m.Config.WebSocket.Address, m.Config.WebSocket.Port)
ws := websocket.NewServer(addr)
err = ws.ListenAndServe()
`
LC: Local Controller
LC はエッジノード上で動き、ローカルジョブ管理とメッセージ中継を担う。エントリは
cmd/sedna-lc/sedna-lc.go(GM 章と同様の読み方)。ローカルマネージャ登録部分:
cmd/sedna-lc/app/server.go
`go
// runServer runs server
func runServer() {
c := gmclient.NewWebSocketClient(Options)
if err := c.Start(); err != nil {
return
}
dm := dataset.New(c, Options)
mm := model.New(c)
jm := jointinference.New(c)
fm := federatedlearning.New(c)
im := incrementallearning.New(c, dm, mm, Options)
lm := lifelonglearning.New(c, dm, Options)
s := server.New(Options)
for _, m := range []managers.FeatureManager{
dm, mm, jm, fm, im, lm,
} {
s.AddFeatureManager(m)
c.Subscribe(m)
err := m.Start()
if err != nil {
klog.Errorf("failed to start manager %s: %v",
m.GetName(), err)
return
}
klog.Infof("manager %s is started", m.GetName())
}
s.ListenAndServe()
}
`
ローカルジョブ管理
エッジ側のジョブを束ねる
Manager の構造体:
pkg/localcontroller/managers/lifelonglearning/lifelonglearningjob.go
`go
// LifelongLearningJobManager defines lifelong-learning-job Manager
type Manager struct {
Client clienttypes.ClientI
WorkerMessageChannel chan workertypes.MessageContent
DatasetManager *dataset.Manager
LifelongLearningJobMap map[string]*Job
VolumeMountPrefix string
}
`
startJob() の流れの要点:
エッジに同期された Dataset を監視し、サンプル数しきい値などで学習トリガーを判断
フェーズに応じて学習/評価/デプロイ処理を呼ぶ。実際の Pod 起動は GM 側オーケストレーションに任せ、LC は状態を GM に報告する
pkg/localcontroller/managers/lifelonglearning/lifelonglearningjob.go
`go
// startJob starts a job
func (lm *Manager) startJob(name string) {
...
// 监控并处理同步到边缘的Dataset对象。
go lm.handleData(job)
tick := time.NewTicker(JobIterationIntervalSeconds * time.Second)
for {
// 根据当前任务不同阶段,触发不同阶段的训练、评估、部署任务。
select {
case <-job.JobConfig.Done:
return
case <-tick.C:
cond := lm.getLatestCondition(job)
jobStage := cond.Stage
switch jobStage {
case sednav1.LLJobTrain:
err = lm.trainTask(job)
case sednav1.LLJobEval:
err = lm.evalTask(job)
case sednav1.LLJobDeploy:
err = lm.deployTask(job)
default:
klog.Errorf("invalid phase: %s", jobStage)
continue
}
...
}
}
}
`
ほかにもデータセット監視、モデル取得、ローカル DB バックアップなどがある。
メッセージプロキシ
状態変化はクラウドへ送るほか、ローカル
0.0.0.0:9100 で HTTP サーバを立て、Lib からのワーカー報告を集約して GM へ転送する。REST ルート例:
pkg/localcontroller/server/server.go
`go
// register registers api
func (s Server) register(container restful.Container) {
ws := new(restful.WebService)
ws.Path(fmt.Sprintf("/%s", constants.ServerRootPath)).
Consumes(restful.MIME_XML, restful.MIME_JSON).
Produces(restful.MIME_JSON, restful.MIME_XML)
ws.Route(ws.POST("/workers/{worker-name}/info").
To(s.messageHandler).
Doc("receive worker message"))
container.Add(ws)
}
`
pkg/localcontroller/server/server.go
`go
// messageHandler handles message from the worker
func (s Server) messageHandler(request restful.Request, response *restful.Response) {
var err error
workerName := request.PathParameter("worker-name")
workerMessage := workertypes.MessageContent{}
err = request.ReadEntity(&workerMessage)
if workerMessage.Name != workerName || err != nil {
var msg string
if workerMessage.Name != workerName {
msg = fmt.Sprintf("worker name(name=%s) in the api is different from that(name=%s) in the message body",
workerName, workerMessage.Name)
} else {
msg = fmt.Sprintf("read worker(name=%s) message body failed, error: %v", workerName, err)
}
klog.Errorf(msg)
err = s.reply(response, http.StatusBadRequest, msg)
if err != nil {
klog.Errorf("reply messge to worker(name=%s) failed, error: %v", workerName, err)
}
}
if m, ok := s.fmm[workerMessage.OwnerKind]; ok {
m.AddWorkerMessage(workerMessage)
}
err = s.reply(response, http.StatusOK, "OK")
if err != nil {
klog.Errorf("reply message to worker(name=%s) failed, error: %v", workerName, err)
return
}
}
`
Sedna Lib(Python)
Lib は AI/アプリ開発者向けの Python パッケージで、既存コードを協調型に載せ替えやすくする。
ディレクトリ構成:
`plain text
➜ sedna tree lib -L 2
lib
├── __init__.py
├── MANIFEST.in
├── OWNERS
├── requirements.dev.txt
├── requirements.txt // Sedna Pythonの依存
├── sedna
│ ├── algorithms // 協調向けアルゴリズム
│ ├── backend // tensorflow/pytorch 等のバックエンド
│ ├── common
│ ├── core // 各機能の中核ロジック
│ ├── datasources // txt/csv 等のデータソース
│ ├── __init__.py
│ ├── README.md
│ ├── service // KB などサーバが要るコンポーネント
│ ├── VERSION
│ └── __version__.py
└── setup.py
`
代表的なコード片を領域ごとに見る。
core
ユーザーの
train などをラップし、TensorFlow/PyTorch/MindSpore 実装を呼び出す。
後処理コールバックの設定
クラウド KB を介した学習・推論
KB の更新(ライフロングではモデルとサンプルが蓄積される)
進捗・メトリクスを LC へ報告
lib/sedna/core/lifelong_learning/lifelong_learning.py
`python
def train(self, train_data,
valid_data=None,
post_process=None,
**kwargs):
is_completed_initilization = \
str(Context.get_parameters("HAS_COMPLETED_INITIAL_TRAINING",
"false")).lower()
if is_completed_initilization == "true":
return self.update(train_data,
valid_data=valid_data,
post_process=post_process,
**kwargs)
# 配置后处理函数
callback_func = None
if post_process is not None:
callback_func = ClassFactory.get_cls(
ClassType.CALLBACK, post_process)
res, seen_task_index = \
self.cloud_knowledge_management.seen_estimator.train(
train_data=train_data,
valid_data=valid_data,
**kwargs
)
# 调用云端知识库进行训练、或推理
unseen_res, unseen_task_index = \
self.cloud_knowledge_management.unseen_estimator.train()
# 更新云端知识库
task_index = dict(
seen_task=seen_task_index,
unseen_task=unseen_task_index)
task_index_url = FileOps.dump(
task_index, self.cloud_knowledge_management.local_task_index_url)
task_index = self.cloud_knowledge_management.update_kb(task_index_url)
res.update(unseen_res)
...
# 将当前训练任务执行的情况发送给LC,比如训练任务是否完成、训练后的指标是多少
self.report_task_info(
None, K8sResourceKindStatus.COMPLETED.value, task_info_res)
self.log.info(f"Lifelong learning Train task Finished, "
f"KB index save in {task_index}")
return callback_func(self.estimator, res) if callback_func else res
...
`
backend
MSBackend は MindSpore バックエンドの一例。フレームワークごとに train/predict/evaluate を揃えれば、Lib から協調実行へ載せられる。
lib/sedna/backend/mindspore/__init__.py
`python
class MSBackend(BackendBase):
def __init__(self, estimator, fine_tune=True, **kwargs):
super(MSBackend, self).__init__(estimator=estimator,
fine_tune=fine_tune,
**kwargs)
self.framework = "mindspore"
if self.use_npu:
context.set_context(mode=context.GRAPH_MODE,
device_target="Ascend")
elif self.use_cuda:
context.set_context(mode=context.GRAPH_MODE,
device_target="GPU")
else:
context.set_context(mode=context.GRAPH_MODE,
device_target="CPU")
if callable(self.estimator):
self.estimator = self.estimator()
def train(self, train_data, valid_data=None, **kwargs):
if callable(self.estimator):
self.estimator = self.estimator()
if self.fine_tune and FileOps.exists(self.model_save_path):
self.finetune()
self.has_load = True
varkw = self.parse_kwargs(self.estimator.train, **kwargs)
return self.estimator.train(train_data=train_data,
valid_data=valid_data,
**varkw)
def predict(self, data, **kwargs):
if not self.has_load:
self.load()
varkw = self.parse_kwargs(self.estimator.predict, **kwargs)
return self.estimator.predict(data=data, **varkw)
def evaluate(self, data, **kwargs):
if not self.has_load:
self.load()
varkw = self.parse_kwargs(self.estimator.evaluate, **kwargs)
return self.estimator.evaluate(data, **varkw)
`
datasource
CSV などよく使う形式のパースをまとめている。
lib/sedna/datasources/__init__.py
`python
class CSVDataParse(BaseDataSource, ABC):
"""
csv file which contain Structured Data parser
"""
# 提供了方便的数据集解析函数,
def parse(self, args, *kwargs):
x_data = []
y_data = []
label = kwargs.pop("label") if "label" in kwargs else ""
usecols = kwargs.get("usecols", "")
if usecols and isinstance(usecols, str):
usecols = usecols.split(",")
if len(usecols):
if label and label not in usecols:
usecols.append(label)
kwargs["usecols"] = usecols
for f in args:
if isinstance(f, (dict, list)):
res = self.parse_json(f, **kwargs)
else:
if not (f and FileOps.exists(f)):
continue
res = pd.read_csv(f, **kwargs)
if self.process_func and callable(self.process_func):
res = self.process_func(res)
if label:
if label not in res.columns:
continue
y = res[label]
y_data.append(y)
res.drop(label, axis=1, inplace=True)
x_data.append(res)
if not x_data:
return
self.x = pd.concat(x_data)
self.y = pd.concat(y_data)
`
algorithms
協調 AI 向けに、難例マイニング(HEM)などを同梱する。例として交差エントロピーしきい値で「モデルが自信がない」サンプルを拾う。
Lib はこれらの基礎実装にとどまらず、協調フレームワーク上でアルゴリズムを差し替え・拡張して全体の学習/推論品質を上げることを狙う。
lib/sedna/algorithms/hard_example_mining/hard_example_mining.py
`python
@ClassFactory.register(ClassType.HEM, alias="CrossEntropy")
class CrossEntropyFilter(BaseFilter, abc.ABC):
"""
Object detection Hard samples discovery methods named
CrossEntropy
Parameters
----------
threshold_cross_entropy: float
hard coefficient threshold score to filter img, default to 0.5.
"""
def __init__(self, threshold_cross_entropy=0.5, **kwargs):
self.threshold_cross_entropy = float(threshold_cross_entropy)
def __call__(self, infer_result=None) -> bool:
"""judge the img is hard sample or not.
Parameters
----------
infer_result: array_like
prediction classes list, such as
[class1-score, class2-score, class2-score,....],
where class-score is the score corresponding to the class,
class-score value is in [0,1], who will be ignored if its
value not in [0,1].
Returns
-------
is hard sample: bool
True means hard sample, False means not.
"""
if not infer_result:
# if invalid input, return False
return False
log_sum = 0.0
data_check_list = [class_probability for class_probability
in infer_result
if self.data_check(class_probability)]
if len(data_check_list) != len(infer_result):
return False
for class_data in data_check_list:
log_sum += class_data * math.log(class_data)
confidence_score = 1 + 1.0 * log_sum / math.log(
len(infer_result))
return confidence_score < self.threshold_cross_entropy
``
1. https://www.redhat.com/en/topics/containers/what-is-a-kubernetes-operator
2. https://developers.redhat.com/articles/2021/06/22/kubernetes-operators-101-part-2-how-operators-work
]]>























 『WSJ.』: パンデミック後の中国経済への見通しは。下向きの段階に入るのは運命づけられているか。
張維迎: 数十年の高成長のあと、速度は必ず下がる。公表データどおりの規模なら、安定して 3% を維持できればすでにすごい。これまでの発展モデルは、市場で検証済みの技術をベースにし、R&D 費をかけず投産すれば売れるから速かった。フロンティアに近づくほど自然に遅くなる。恥ずかしいことではない。悪いから遅いのではなく、うまくやっても遅くなる。
『WSJ.』: パンデミック後の中国経済への見通しは。下向きの段階に入るのは運命づけられているか。
張維迎: 数十年の高成長のあと、速度は必ず下がる。公表データどおりの規模なら、安定して 3% を維持できればすでにすごい。これまでの発展モデルは、市場で検証済みの技術をベースにし、R&D 費をかけず投産すれば売れるから速かった。フロンティアに近づくほど自然に遅くなる。恥ずかしいことではない。悪いから遅いのではなく、うまくやっても遅くなる。
 『WSJ.』: 資本批判はいったん退潮したように見える。世界経済の下振れのなかで 996 が一部の人に「福報」と言われるような転換をどう見るか。
張維迎: 繰り返し言っているが、社長は社員より苦労するのが普通で、勤務時間も長い。
『WSJ.』: 資本批判はいったん退潮したように見える。世界経済の下振れのなかで 996 が一部の人に「福報」と言われるような転換をどう見るか。
張維迎: 繰り返し言っているが、社長は社員より苦労するのが普通で、勤務時間も長い。
 『WSJ.』: 企業家精神はある意味輸入品か。中国に自発的企業家精神の素地はあるか。
張維迎: 我々のなかには常に落ち着かない人がいる。何かしたい。他人がしたがらないかできないことをしたい。衝動があり、リスクを取り、失敗も受け入れる。古今にいた。人類はアフリカから出たが、誰が出たか。企業家精神のある人だ。
『WSJ.』: 企業家精神はある意味輸入品か。中国に自発的企業家精神の素地はあるか。
張維迎: 我々のなかには常に落ち着かない人がいる。何かしたい。他人がしたがらないかできないことをしたい。衝動があり、リスクを取り、失敗も受け入れる。古今にいた。人類はアフリカから出たが、誰が出たか。企業家精神のある人だ。
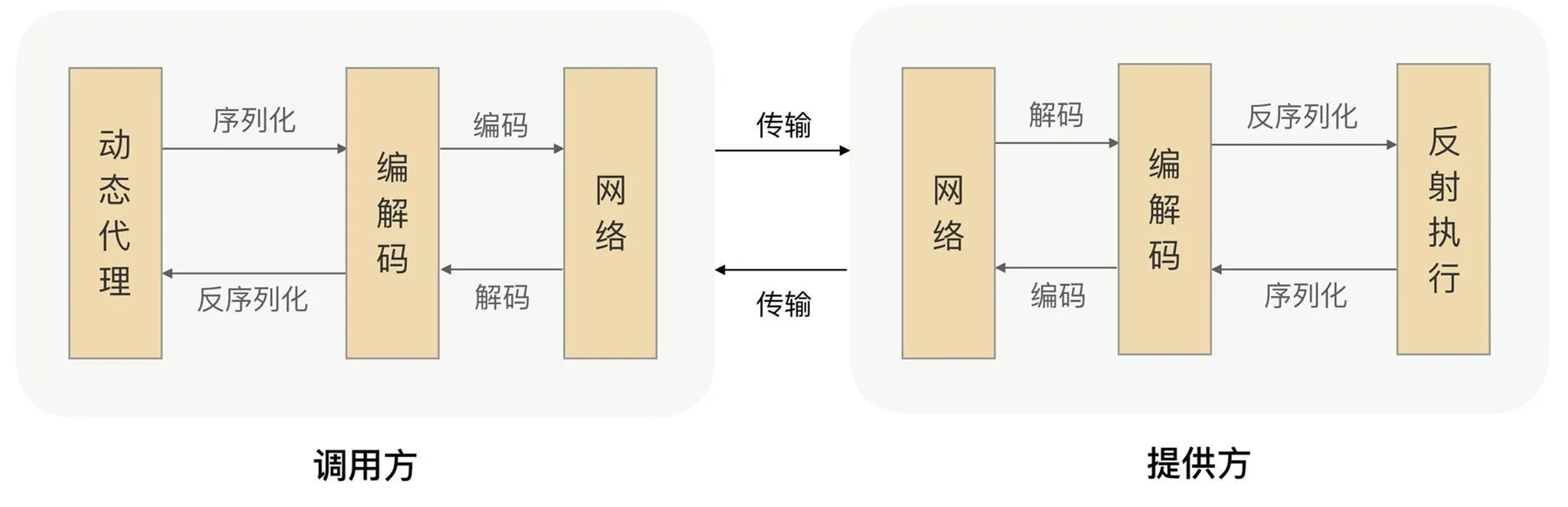
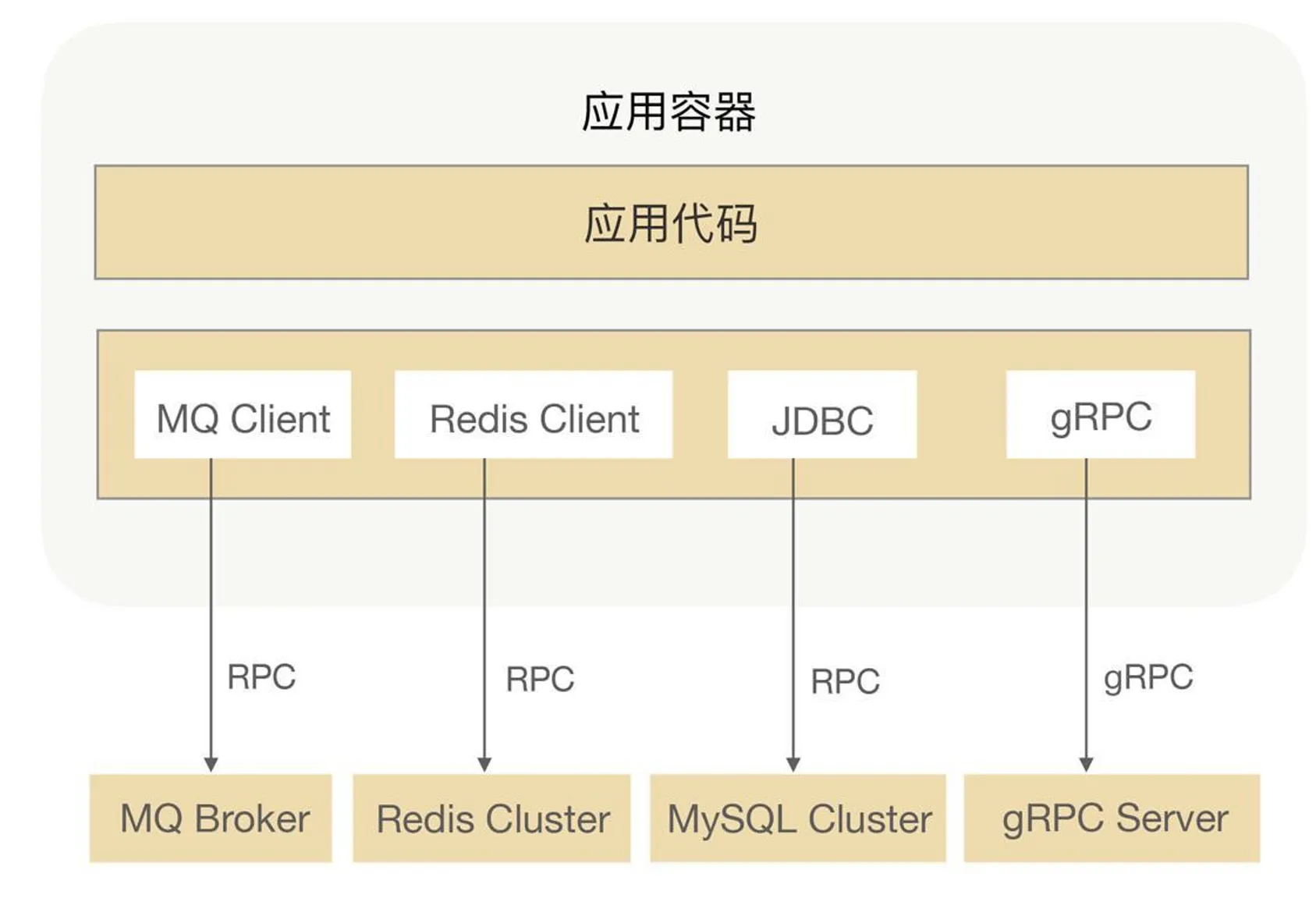

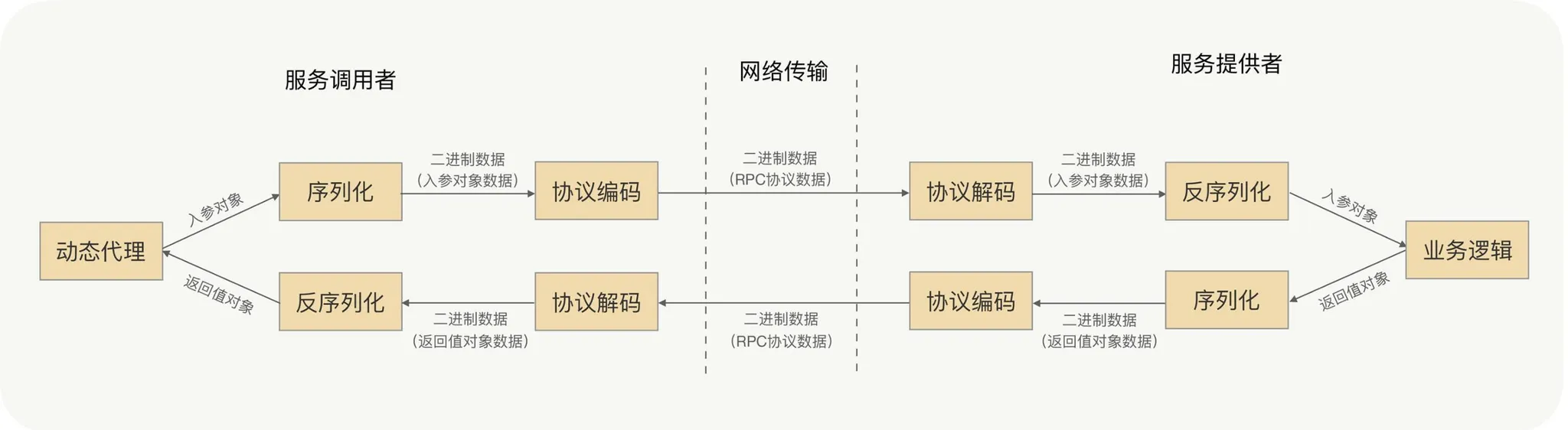

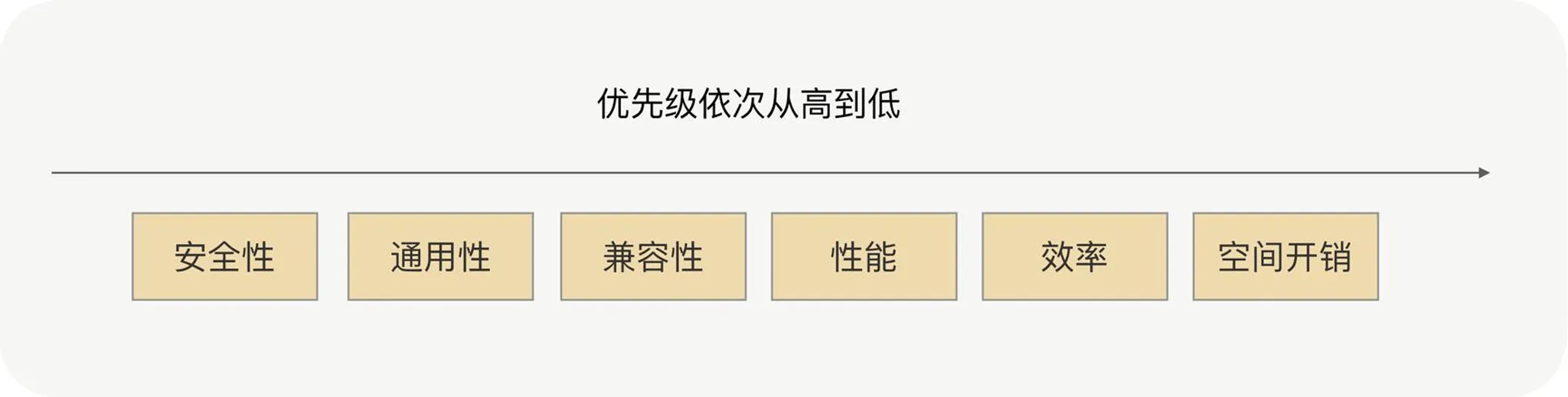
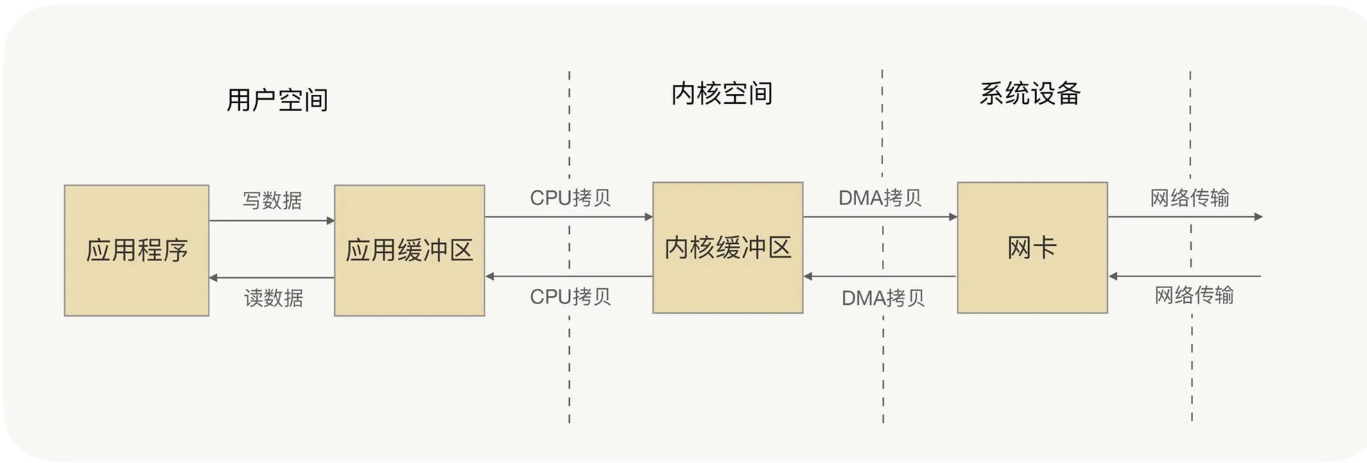
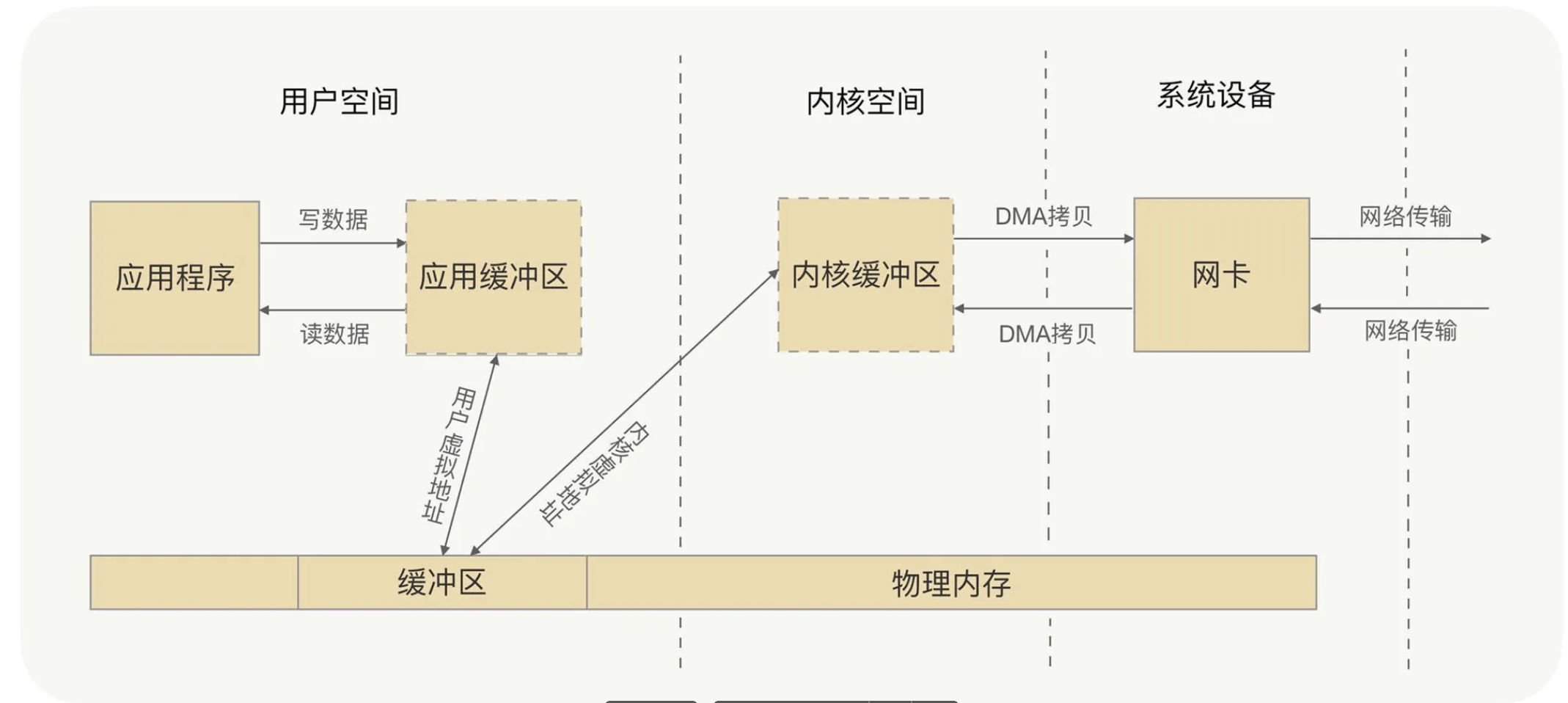
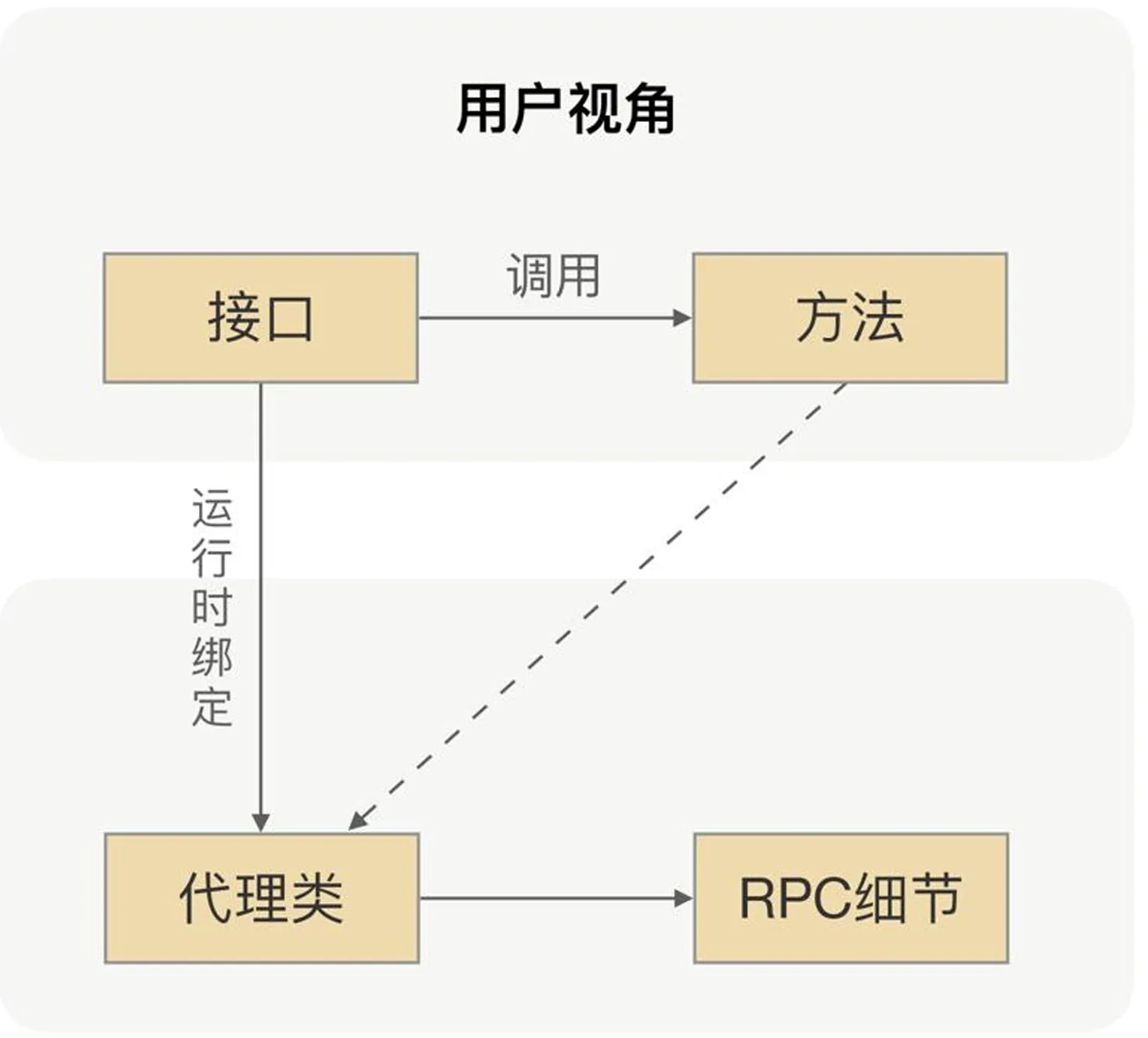
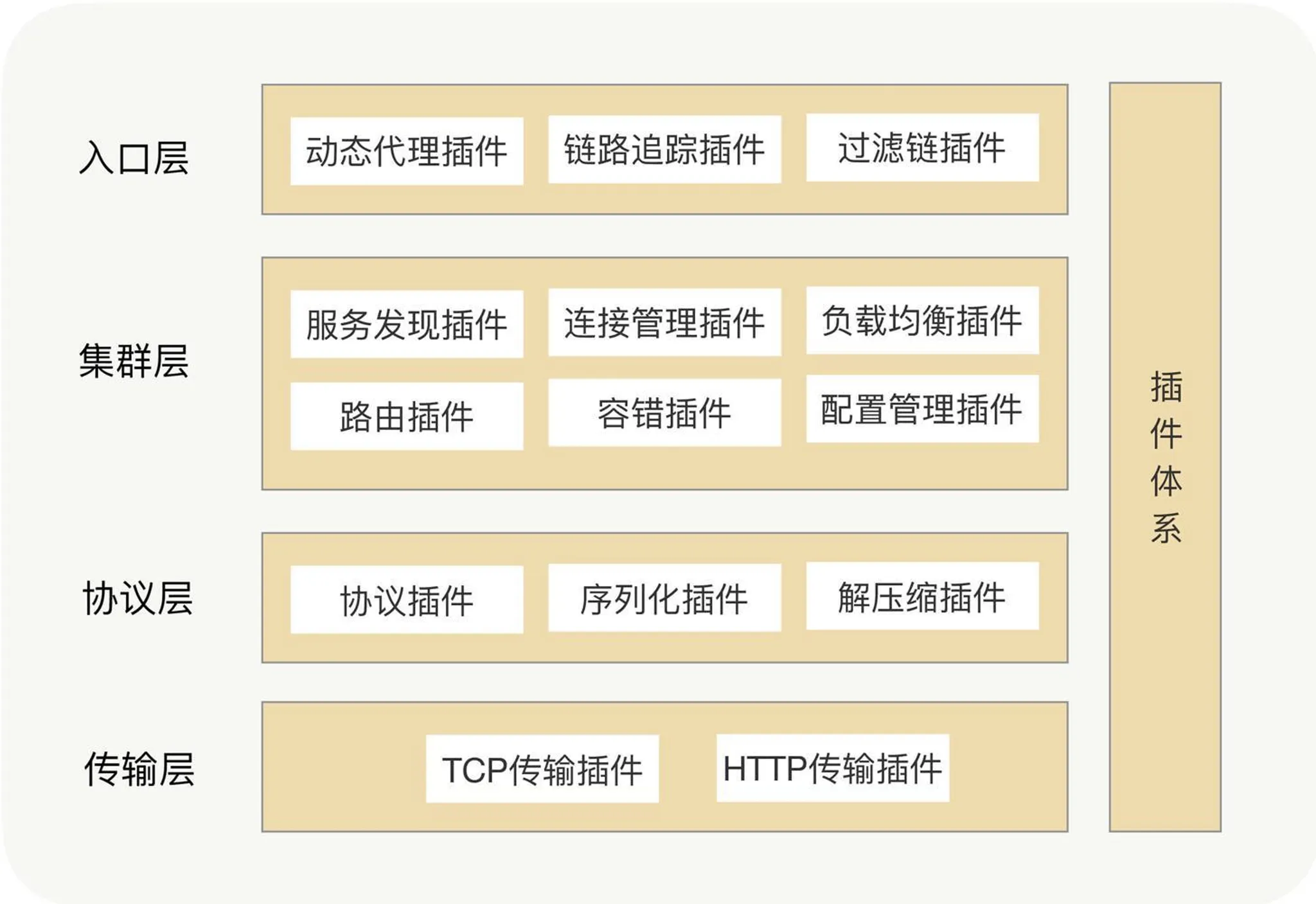
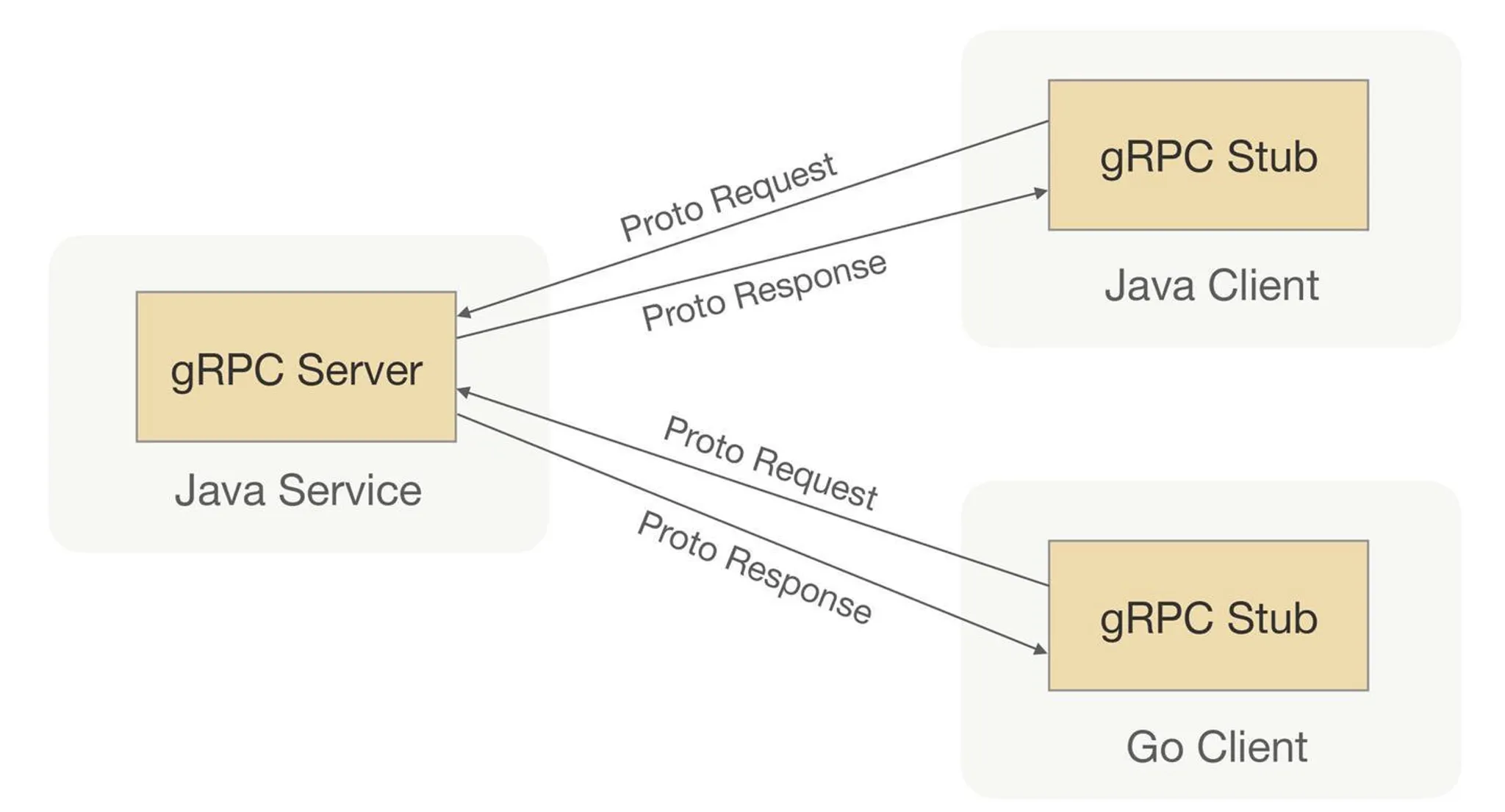 プロトコルカプセル化
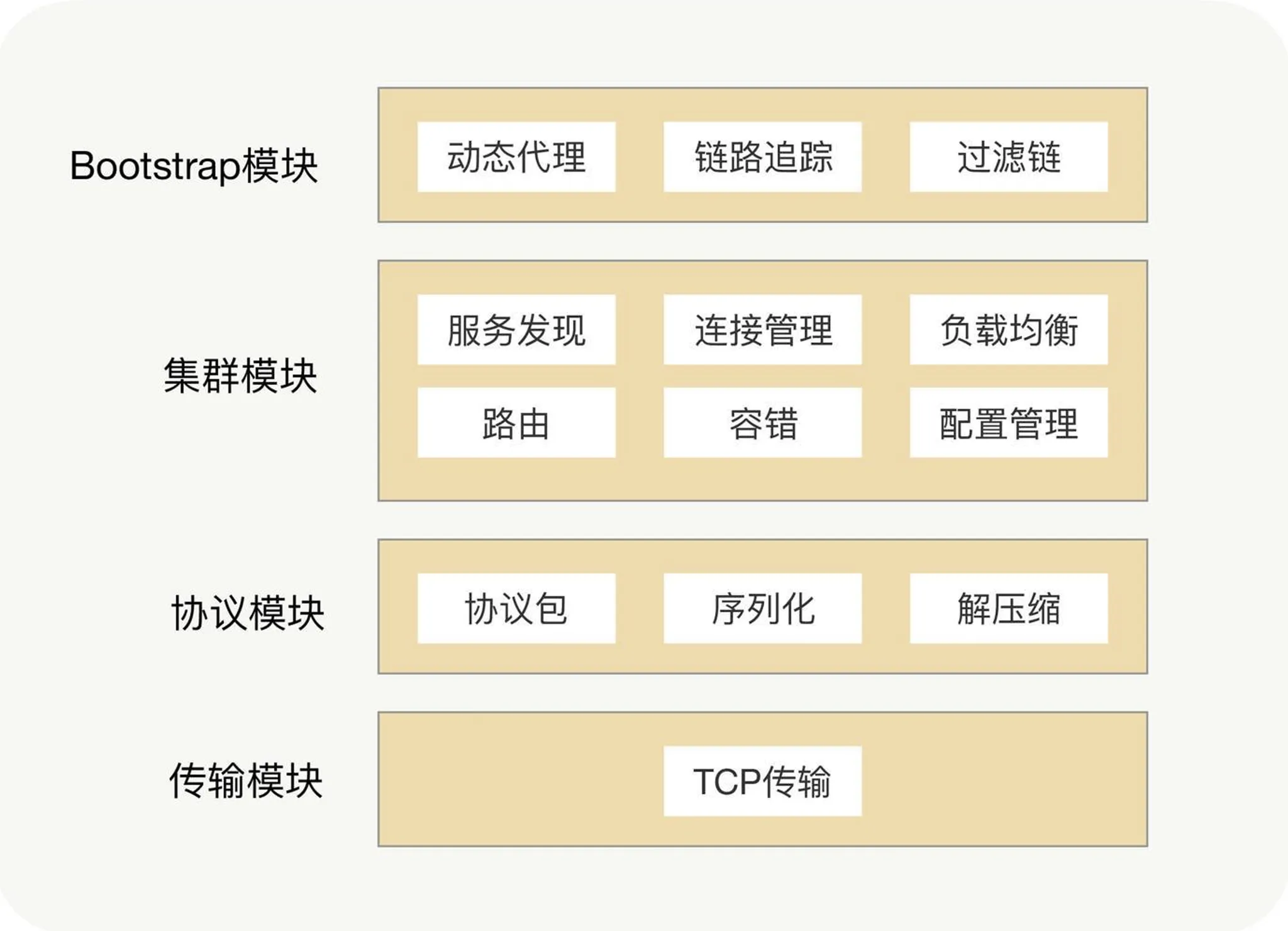
プロトコルカプセル化
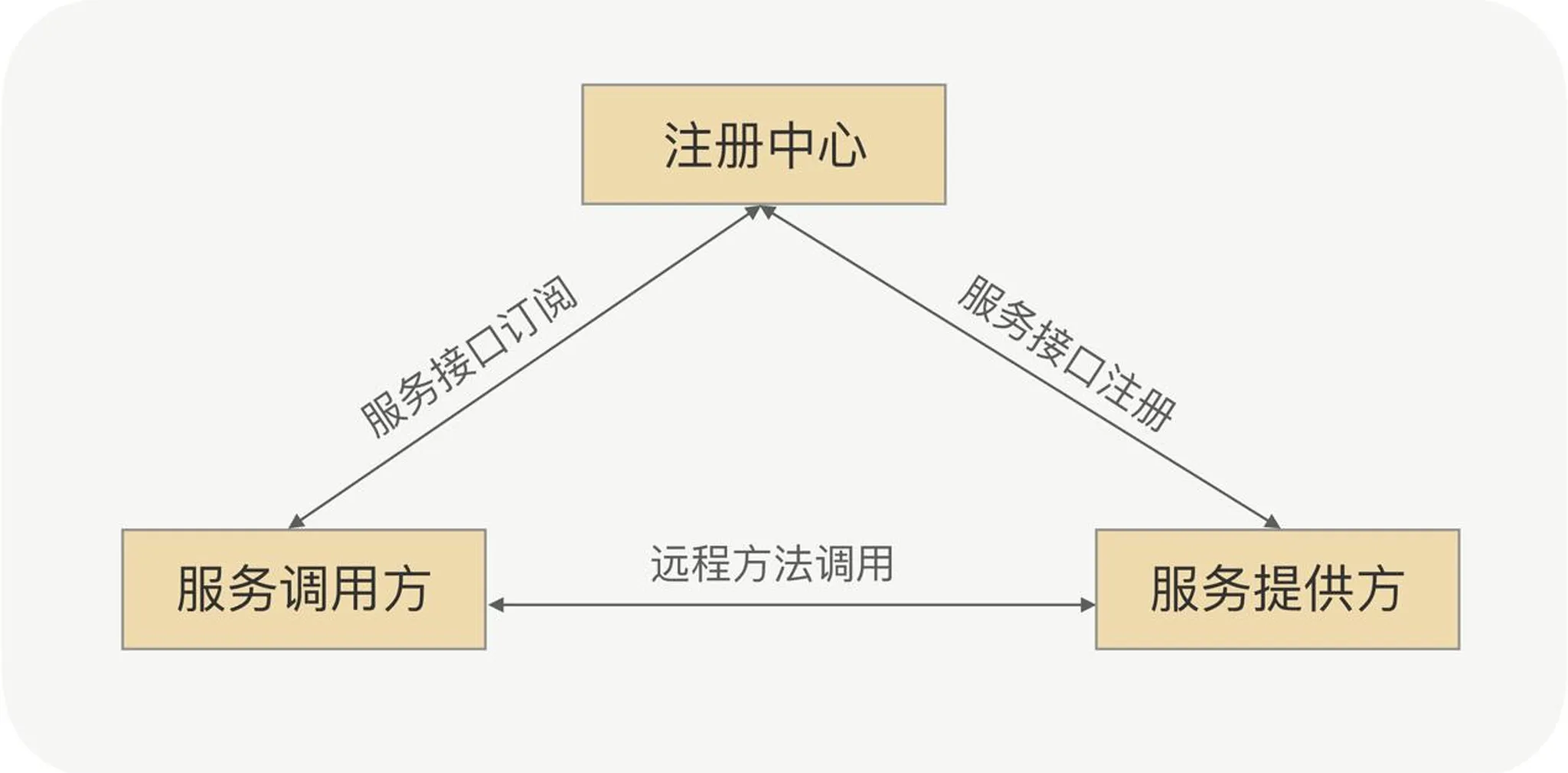
 サービス発見:CP か AP か
サービス発見:CP か AP か
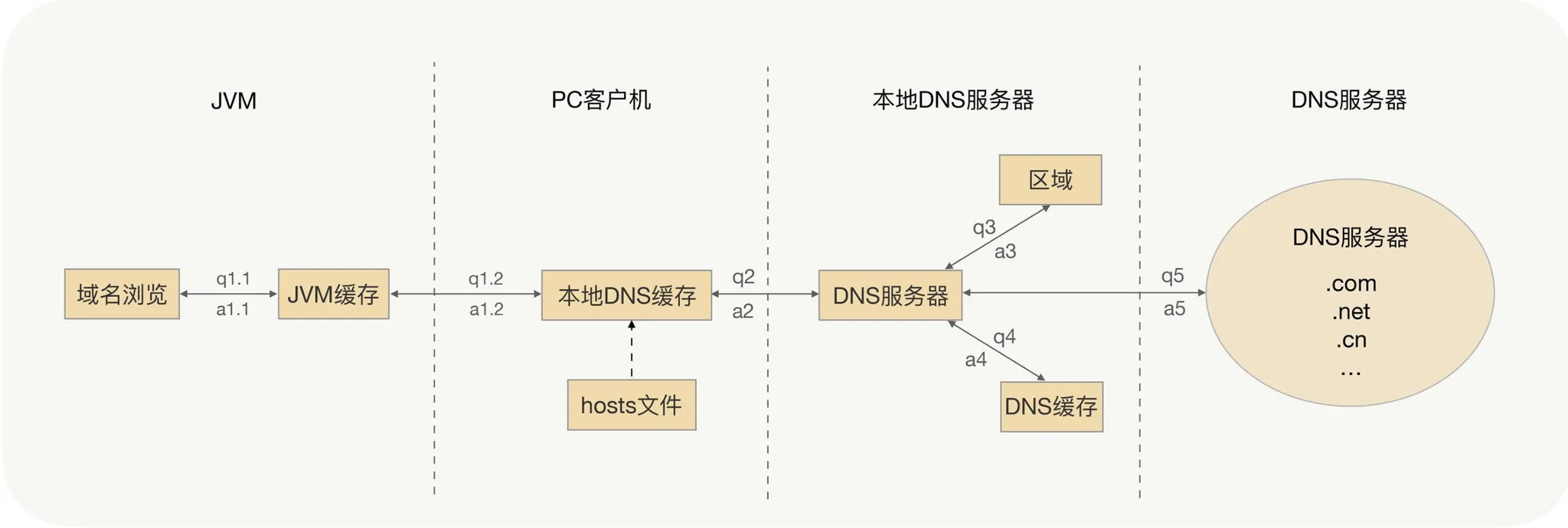 DNS でのサービス発見
DNS でのサービス発見