RPC-learning-notes-en
RPC — Remote Procedure Call — solves communication in distributed systems. The key idea is invoking remote logic as if it were local. RPC is not only a “microservices/cloud-native” buzzword: whenever you cross the network, you may be using RPC.
Examples:
- Large distributed apps talk to message queues, distributed caches, databases, and config centers over RPC. etcd clients speak to the server with gRPC.
- Kubernetes is inherently distributed; kube-apiserver talks to cluster components over gRPC.
RPC touches:
- Serialization: objects ↔ bytes (and back), for cross-network / cross-language exchange.
- Compression: less data on the wire, lower bandwidth and latency.
- Protocol: rules for format and interaction—HTTP/2, TCP, UDP, etc.
- Dynamic proxies: hide remote-call plumbing so code looks like local methods—JDK proxies, bytecode enhancement.
- Service registry & discovery: track live instances, enable load balancing and failover—ZooKeeper, Consul, etcd store addresses and metadata.
- Encryption: confidentiality and integrity; mitigate MITM and tampering.
- Network I/O models: efficient, stable communication—connections, send/receive, and much more (peer lookup, connection setup, encode/decode, connection lifecycle). RPC wraps this stack so building distributed systems is simpler and safer.
At cluster scale you also care about:
- Monitoring
- Circuit breaking & rate limiting
- Graceful startup/shutdown
- Multiple protocols
- Distributed tracing
Where RPC frameworks really shine:
- Connection management
- Health checks
- Load balancing
- Graceful lifecycle
- Retry on failure
- Traffic / tenant grouping
- Circuit breaking & rate limiting
Without an RPC framework you’d still call another machine—but you’d hand-roll all of the above.
RPC hides network details so remote calls feel like in-process methods, without boilerplate unrelated to your domain.
Two big wins:
- Blur the line between local and remote calls.
- Hide low-level networking so you focus on business logic.
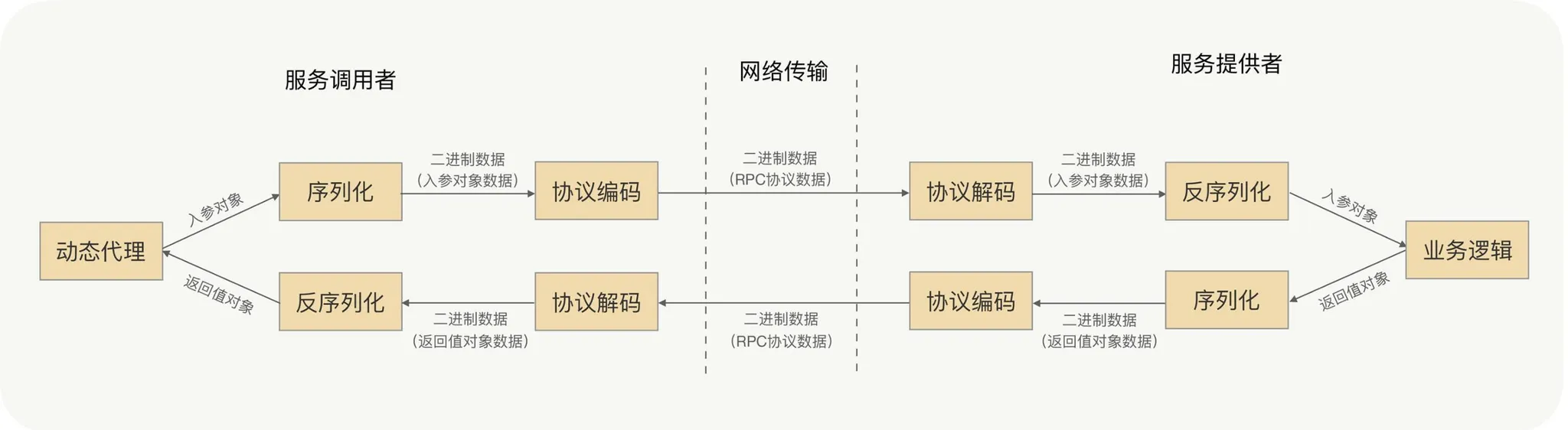
Serialization
On the wire everything is bytes, yet call parameters are objects—you need a reversible mapping to binary.
Message headers usually carry protocol id, length, request type, serializer type, etc.; the body carries business fields and extensions.
Deserialization
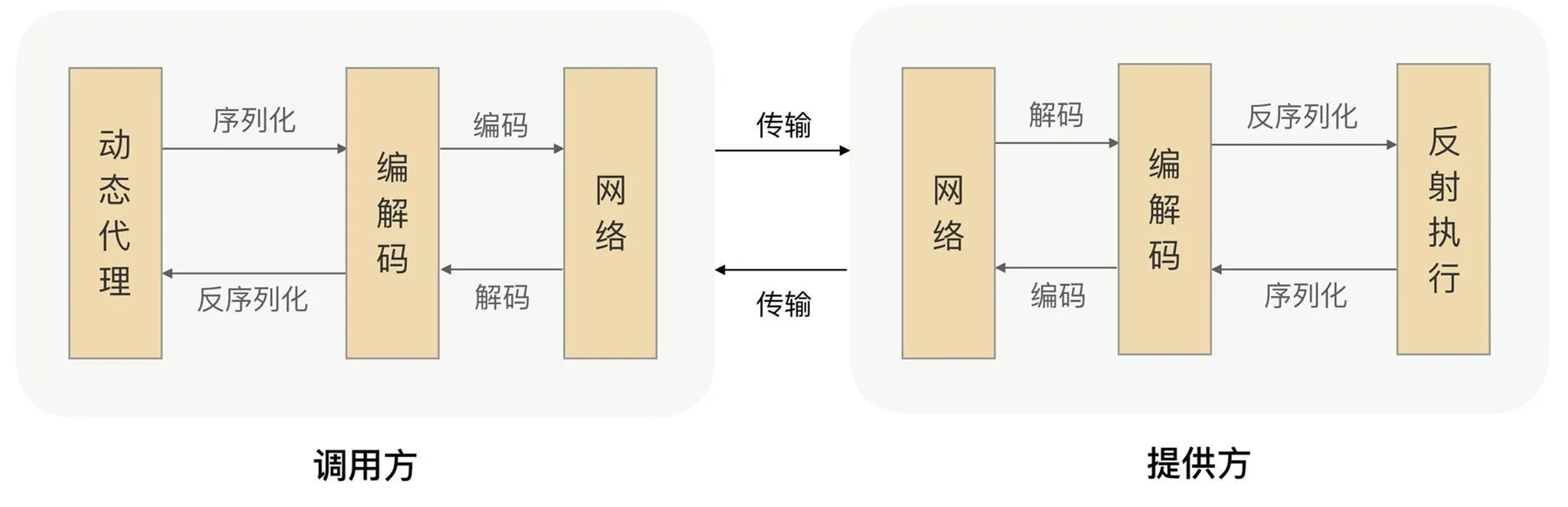
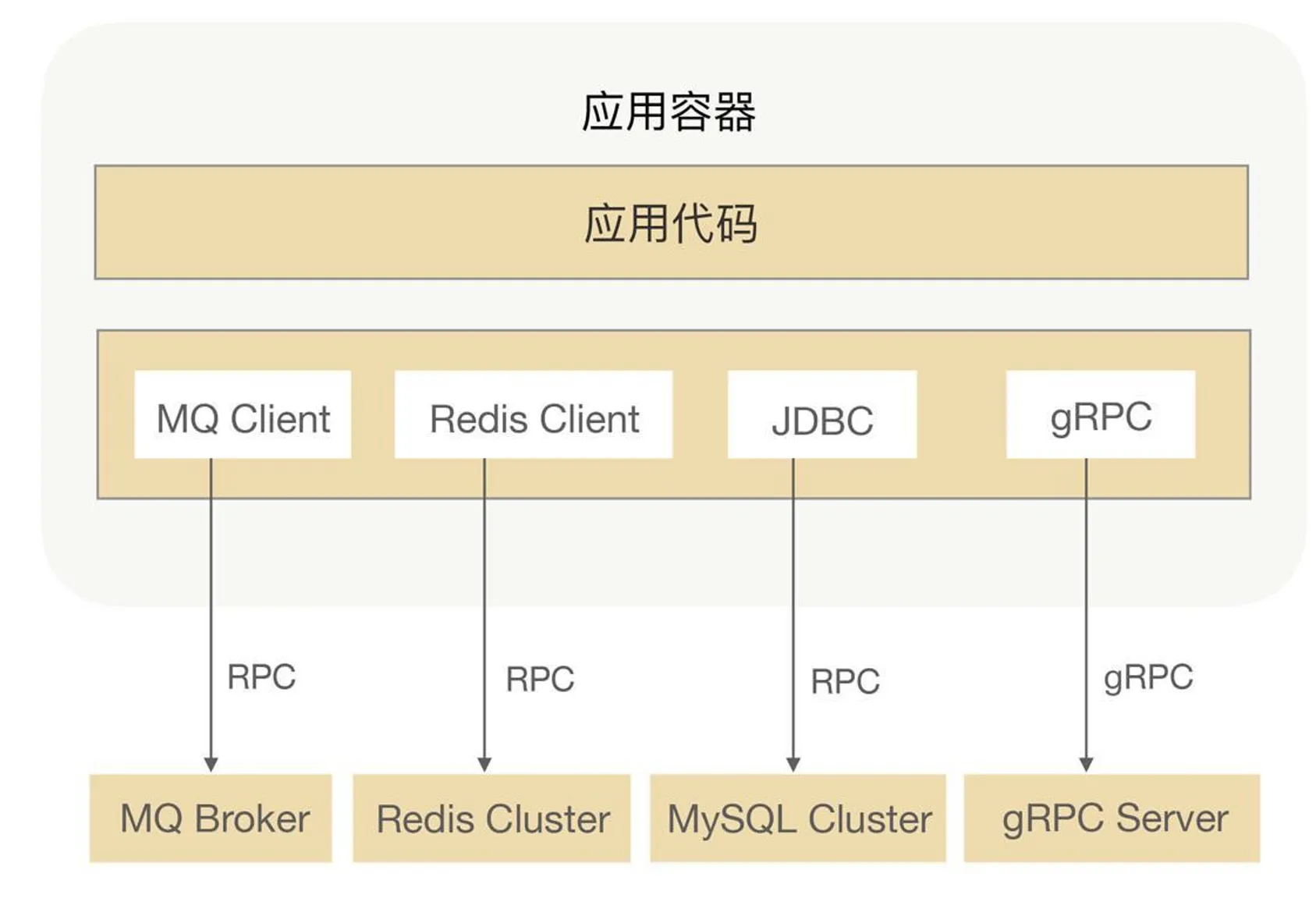
RPC-style stacks also underpin messaging, distributed caches, and databases.
RPC and HTTP both live at the application layer.
Before hitting the network, the client serializes the call arguments to bytes, writes them to a local socket, and the NIC sends them out.
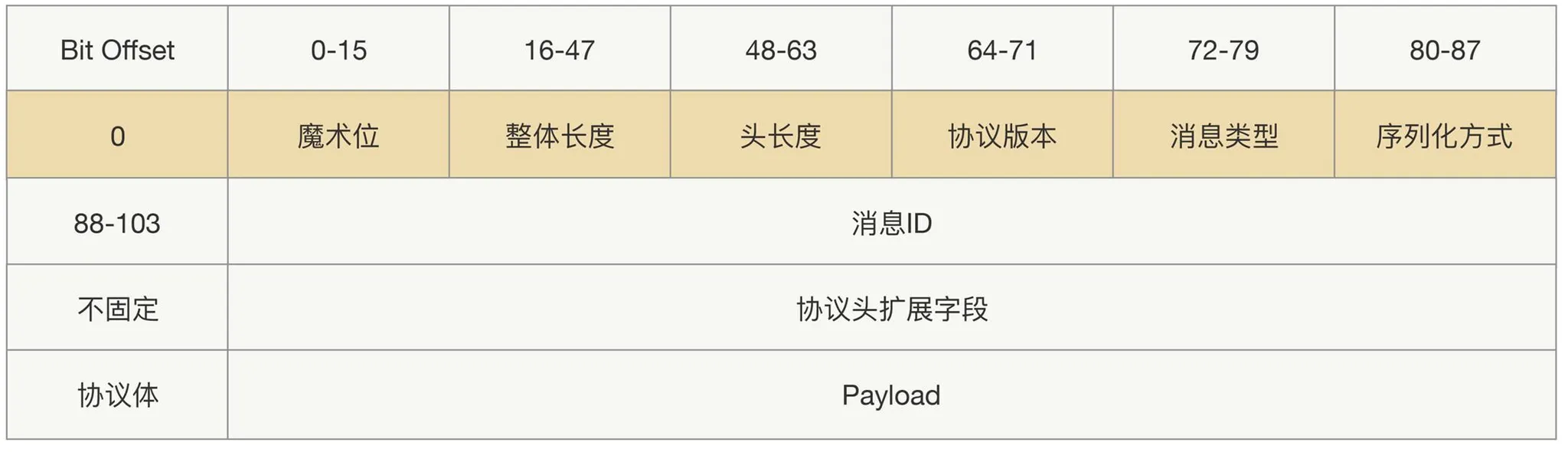
For an evolvable, backward-compatible protocol, lean on extensible header and payload fields.
Pick serializers per scenario.
Common choices:
- JDK native serialization

Every serializer is really a wire protocol design.
- JSON: key/value text, weak typing. Downsides: bulky on the wire; in Java you pay reflection cost. Fine only when payloads stay small.
- Hessian: dynamic, binary, compact, multi-language. Smaller/faster than JDK/JSON for many workloads. Caveats in stock Hessian: some Java types missing—Linked* maps/sets (extend
CollectionDeserializer),Locale(extendContextSerializerFactory),Byte/Shortwidening toInteger, etc. - Protobuf: Google’s cross-language structured format. You define IDL, compile stubs per language. Strengths: small payloads, clear semantics without XML parsers, fast encode/decode without reflection per field, decent evolution story. (Some Java-centric tools mirror Protobuf wire format without separate IDL files; corner cases exist.)
Also MessagePack, Kryo, etc. Selection factors:
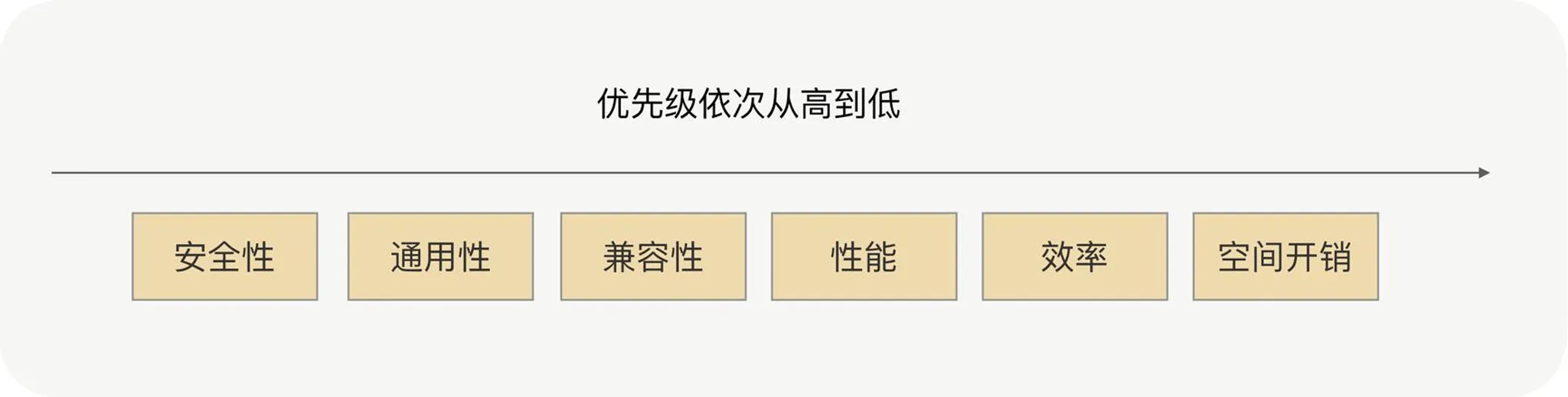
Hessian vs Protobuf are common defaults: both score well on performance, CPU, size, generality, compatibility, and security. Hessian is often easier for Java object graphs; Protobuf wins on efficiency and portability.
Watch out for:
- Overly deep/nested objects.
- Huge messages.
- Parameter types your serializer cannot handle.
- Deep inheritance hierarchies.
Which I/O model?
Common models:
- Blocking IO (BIO)
- Non-blocking IO (NIO)
- I/O multiplexing
- Async IO (AIO)
Only AIO is truly async from the app’s perspective; the rest are synchronous I/O with different waiting styles.
Blocking IO is the default for sockets on Linux: the thread blocks from syscall until data is ready and copied to userspace—two phases: wait, then copy. One blocking socket often means one thread in classic Java servers.
I/O multiplexing (select/poll/epoll) powers high concurrency: NIO, Redis, Nginx, classic Reactor. Many sockets register with a multiplexer; select blocks until some socket is ready, then you read. More moving parts than plain blocking IO, but one thread can progress many sockets—blocking IO would need a thread per socket.
Why BIO + multiplexing dominate: kernels and languages support them widely; signal-driven IO / true async IO need newer kernels. High-performance frameworks (e.g. Netty) are Reactor-style on multiplexing. For low QPS, blocking IO is still common.
RPC servers usually pick multiplexing (plus Reactor frameworks like Netty on Java). On Linux, epoll matters; Windows lacks epoll.
Reactor in one paragraph
Event-driven networking: multiplexing (select/epoll/kqueue) watches many channels; the reactor loop dispatches readiness events to handlers—avoiding a thread per connection.
- Reactor: central event loop + dispatcher.
- Acceptor: accepts connections, registers channels.
- Handlers: read/decode, business logic, encode/write—sometimes offloaded to thread pools.
Zero copy
Kernel I/O still has wait and copy phases.
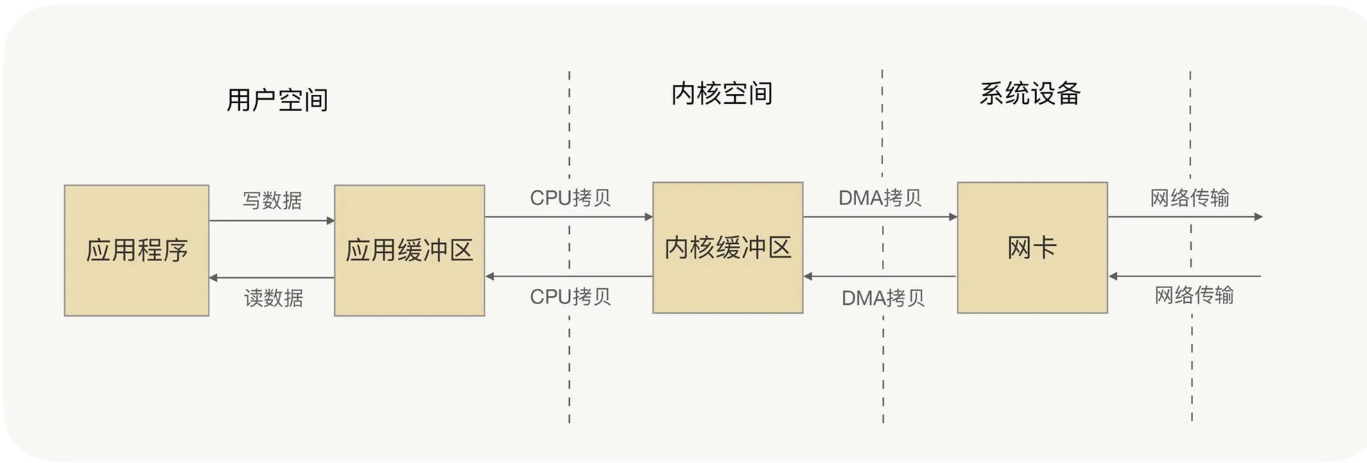
A typical write copies user buffer → kernel buffer → NIC (DMA); reads reverse the path—two copies and two context switches per direction if you count user/kernel boundaries.
Zero-copy avoids redundant user↔kernel copies; DMA still moves data to/from the NIC.
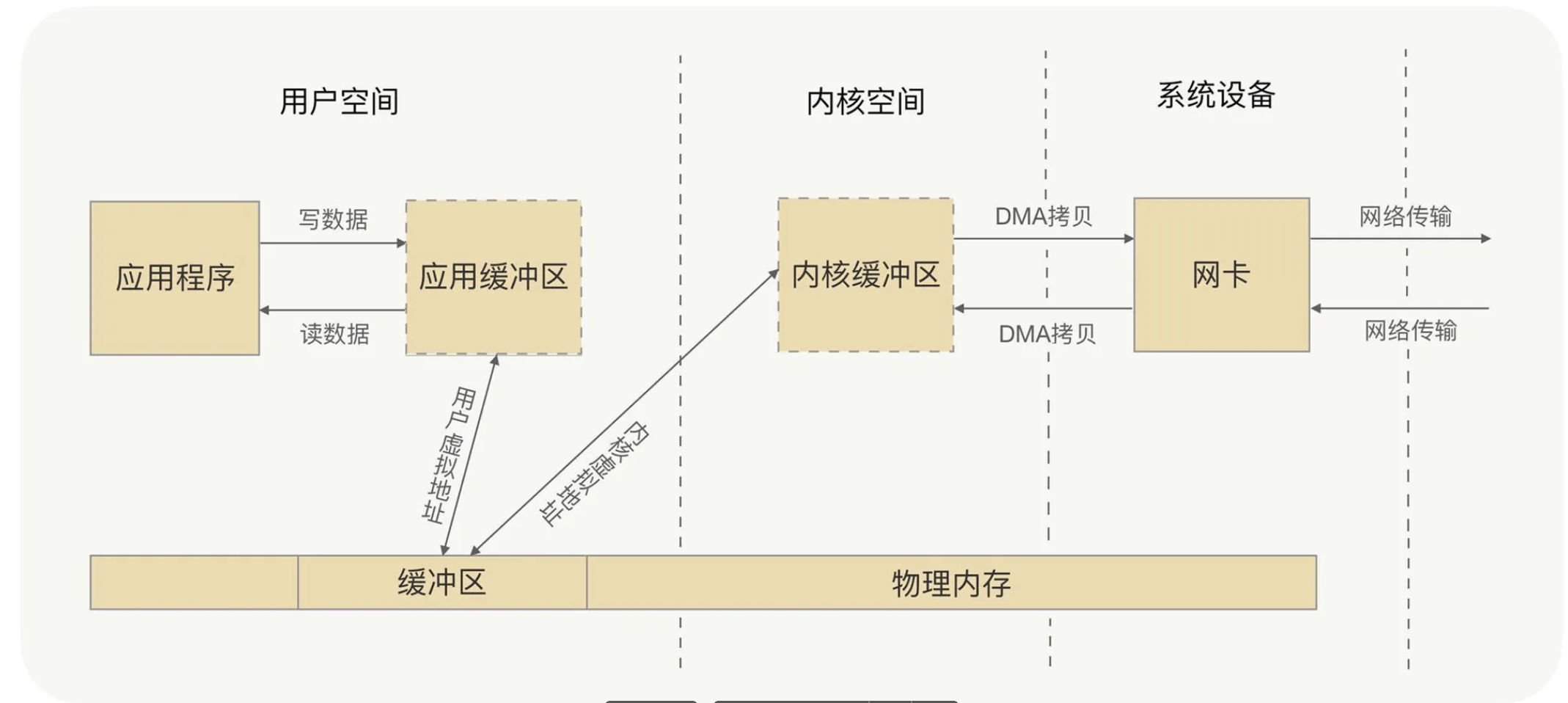
Two main patterns:
mmap+write: map file pages into user space; skip one copy, still multiple transitions; good if you must touch bytes before send.sendfile: kernel-to-kernel path, fewer syscalls; with SG-DMA sometimes only two DMA hops. No user visibility of bytes in flight—best for blind relay of large files.
Pick mmap+write if you must preprocess data; prefer sendfile (especially with SG-DMA) for pure forwarding.
Netty “zero-copy” is mostly JVM-level: CompositeByteBuf, slice, wrap to avoid buffer copies; FileRegion + FileChannel.transferTo() mirrors Linux sendfile.
Dynamic proxies
Interface + generated proxy: dependency injection binds the interface to a proxy that intercepts calls and performs the remote path. (I haven’t stepped through concrete code here.)
Priorities: fast proxy generation, small bytecode, hot-path efficiency, ergonomic APIs, active community, light dependencies.
gRPC
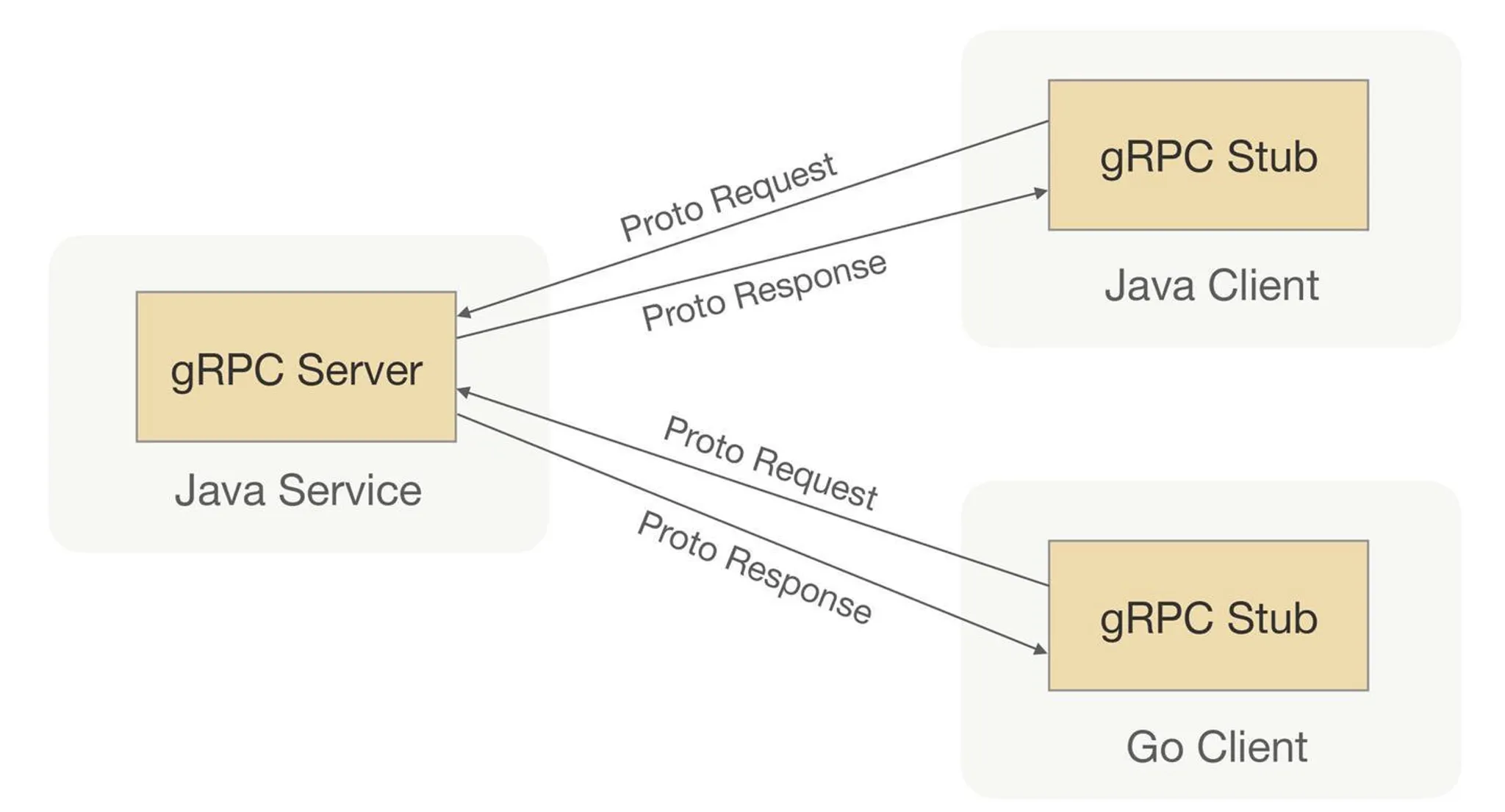
Framing
You need delimiters (“sentence breaks”) around each request’s binary payload so the peer can parse streams of calls—framing / protocol encapsulation.
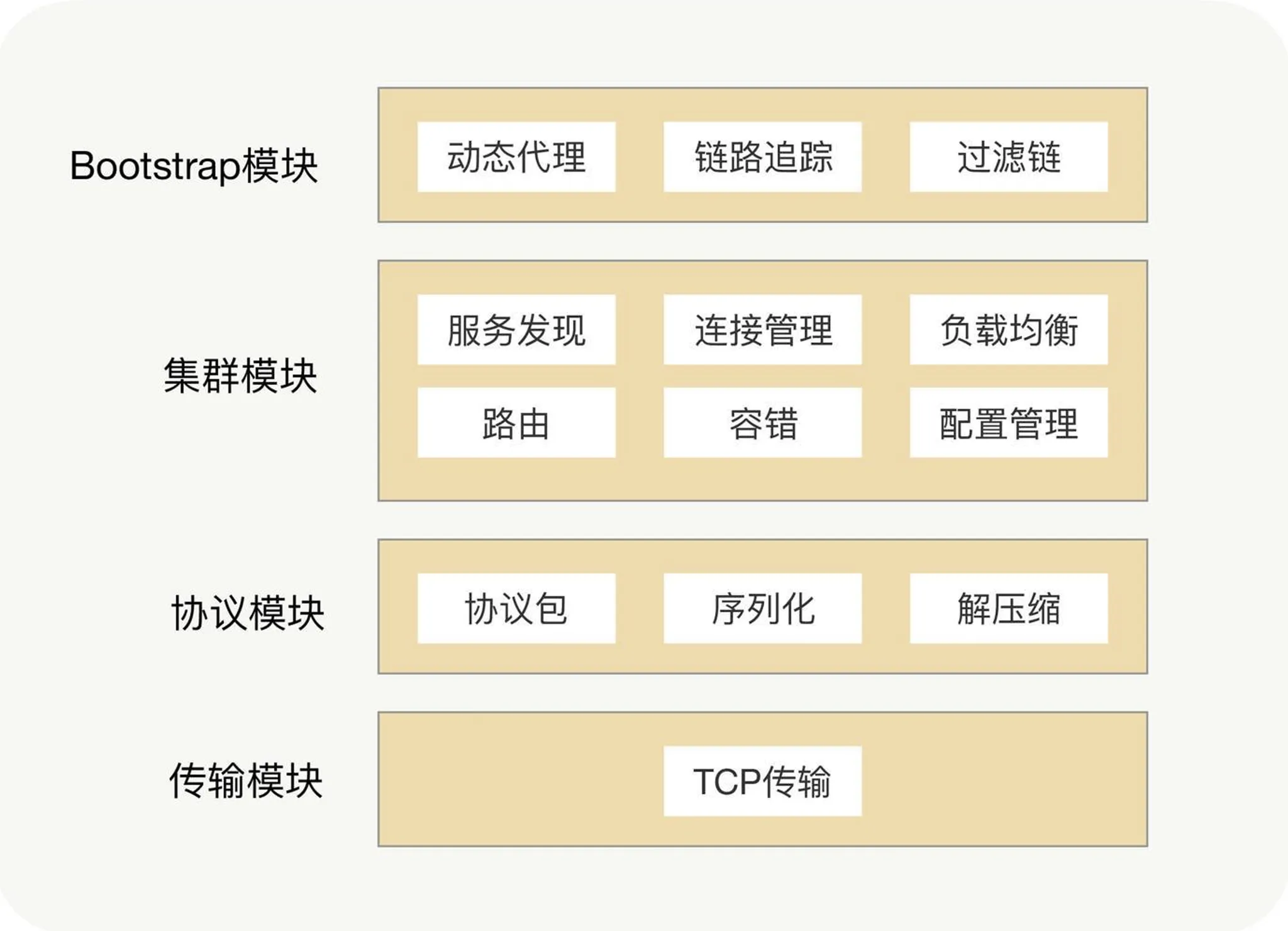
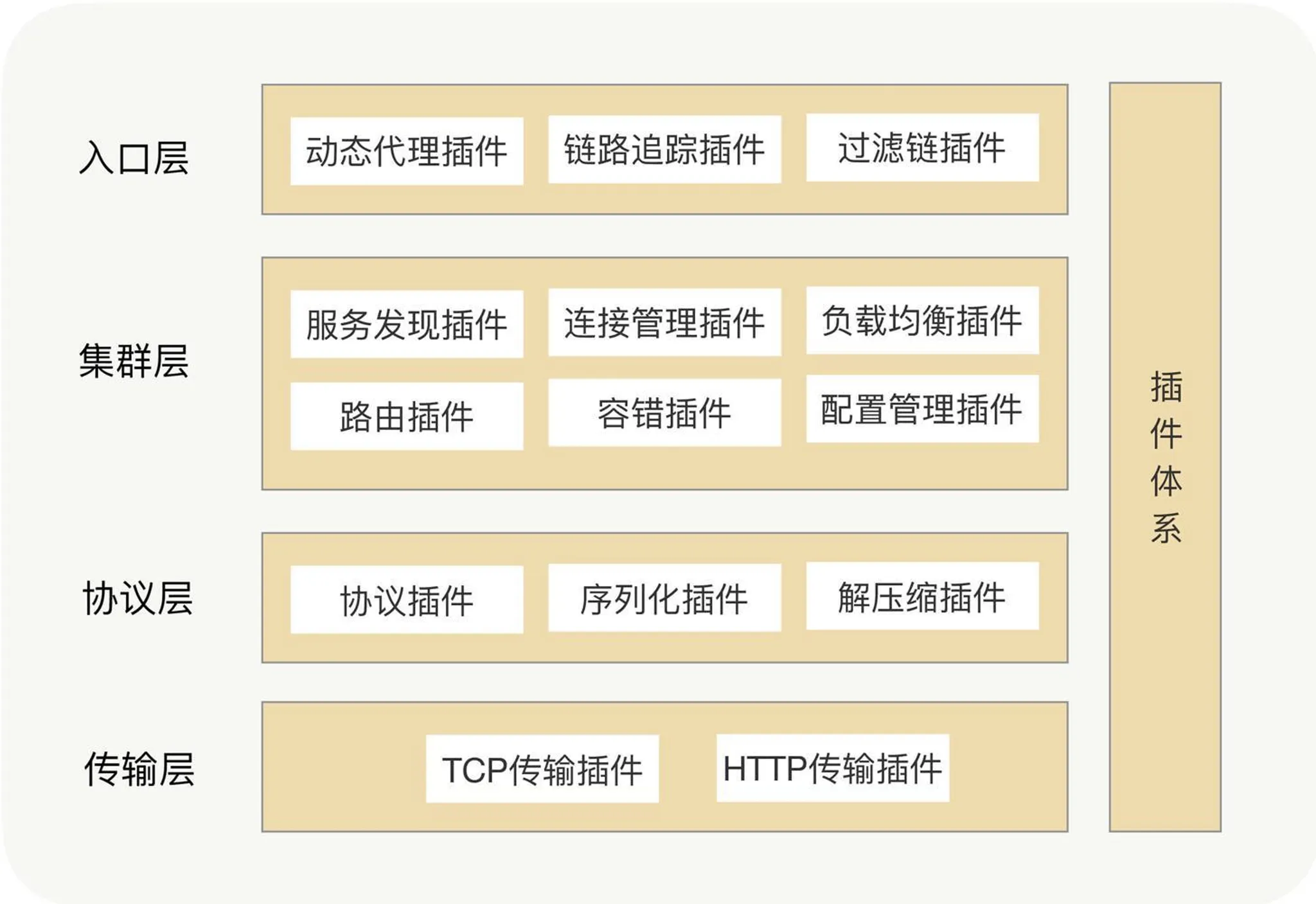
Service discovery: CP or AP?
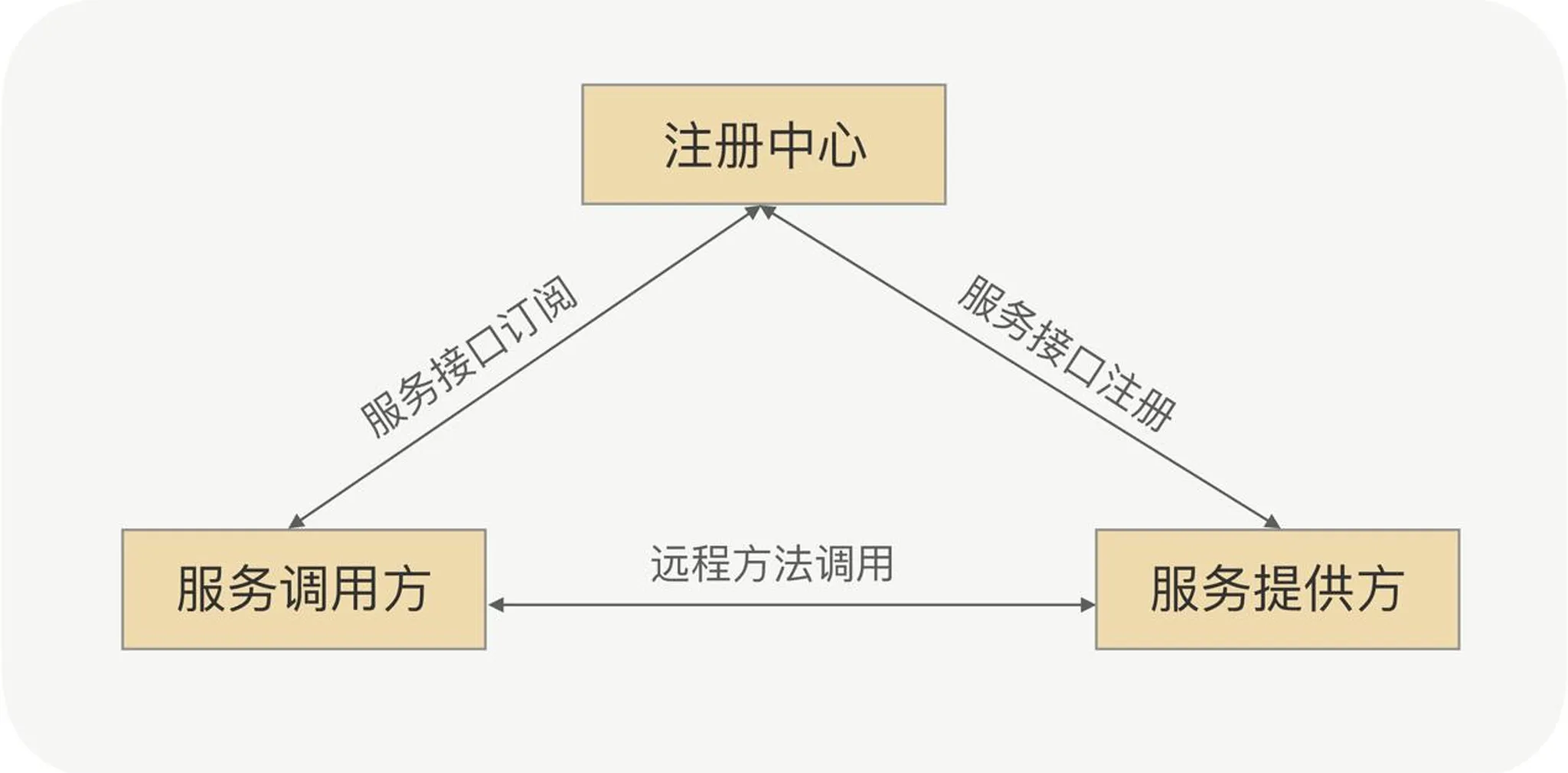
- Registration: providers register endpoints with the registry.
- Subscription: consumers fetch and cache provider addresses for later calls.
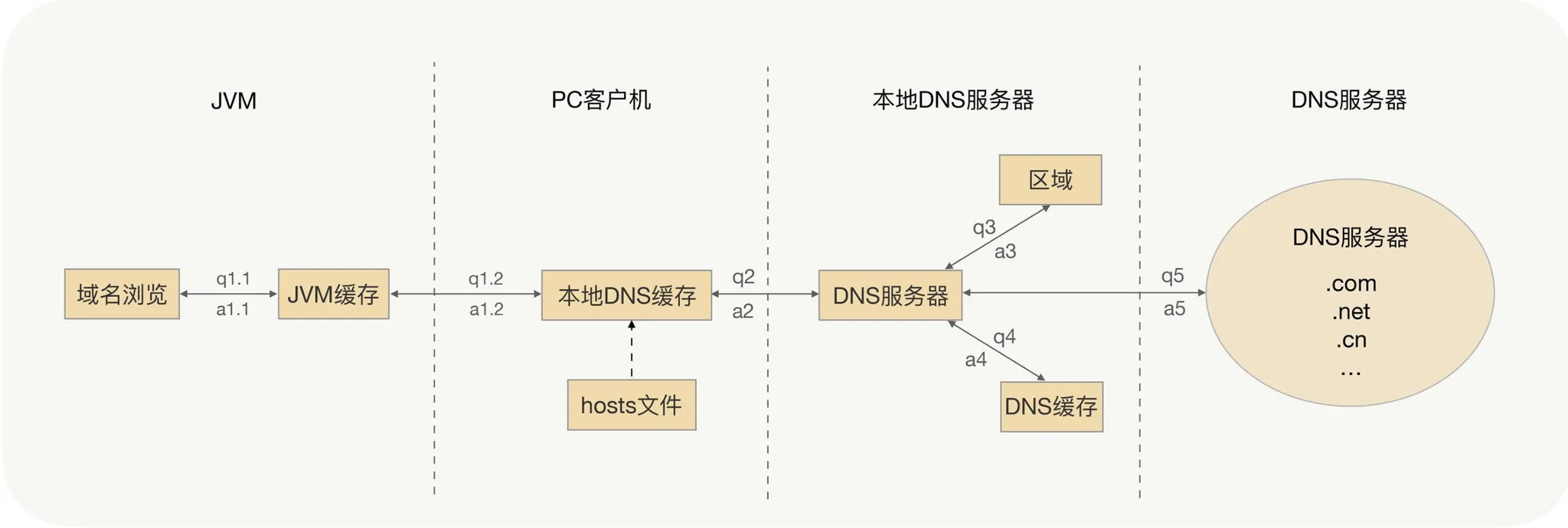
DNS as discovery: all instances behind one name looks fine until you need fast add/remove. DNS TTL and caching mean callers rarely see new nodes or drops immediately—usually no to both “timely drain” and “instant scale-out”.
ZooKeeper-style
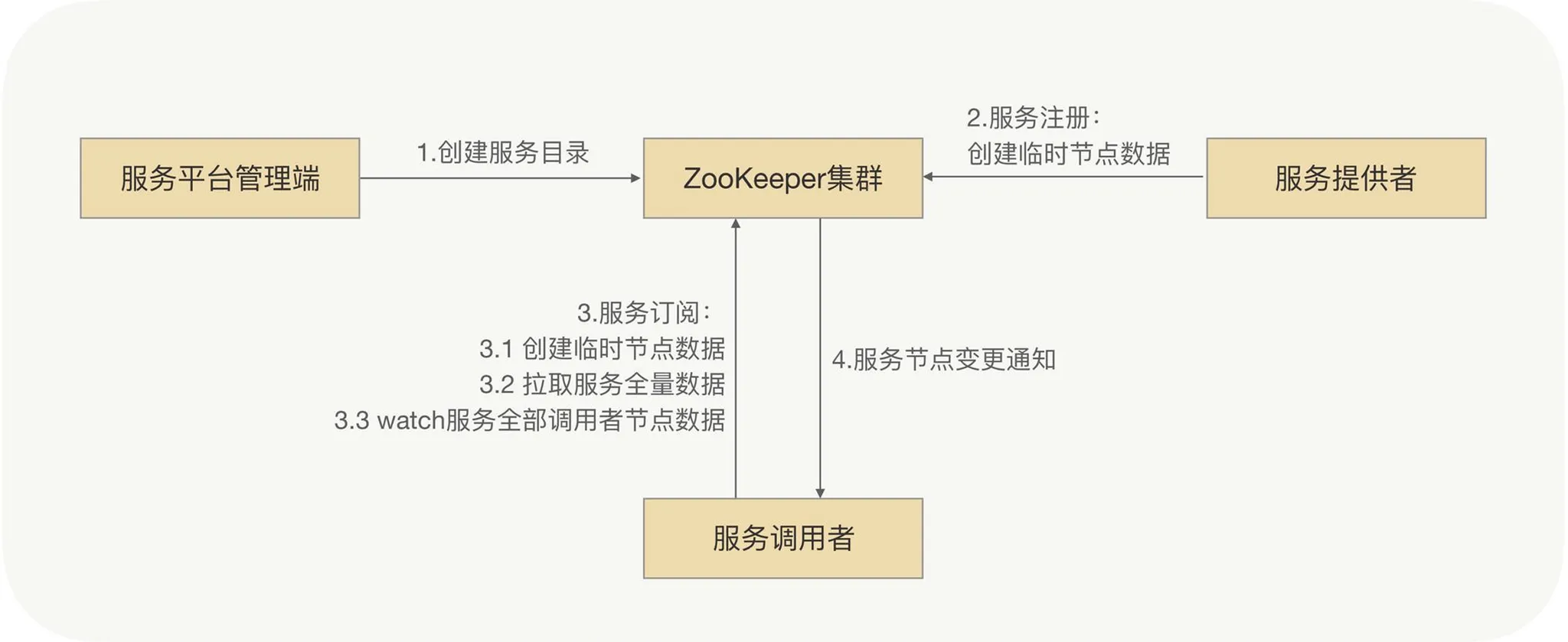
- Admin creates a root znode per service (e.g.
/service/com.demo.xxService), withprovider/consumersubtrees. - Providers create ephemeral nodes under
providerwith metadata. - Consumers create their own ephemeral nodes and watch the
providersubtree. - Any provider change pushes a notification to watchers.
ZK favors strong consistency—every update is replicated synchronously, which limits throughput.
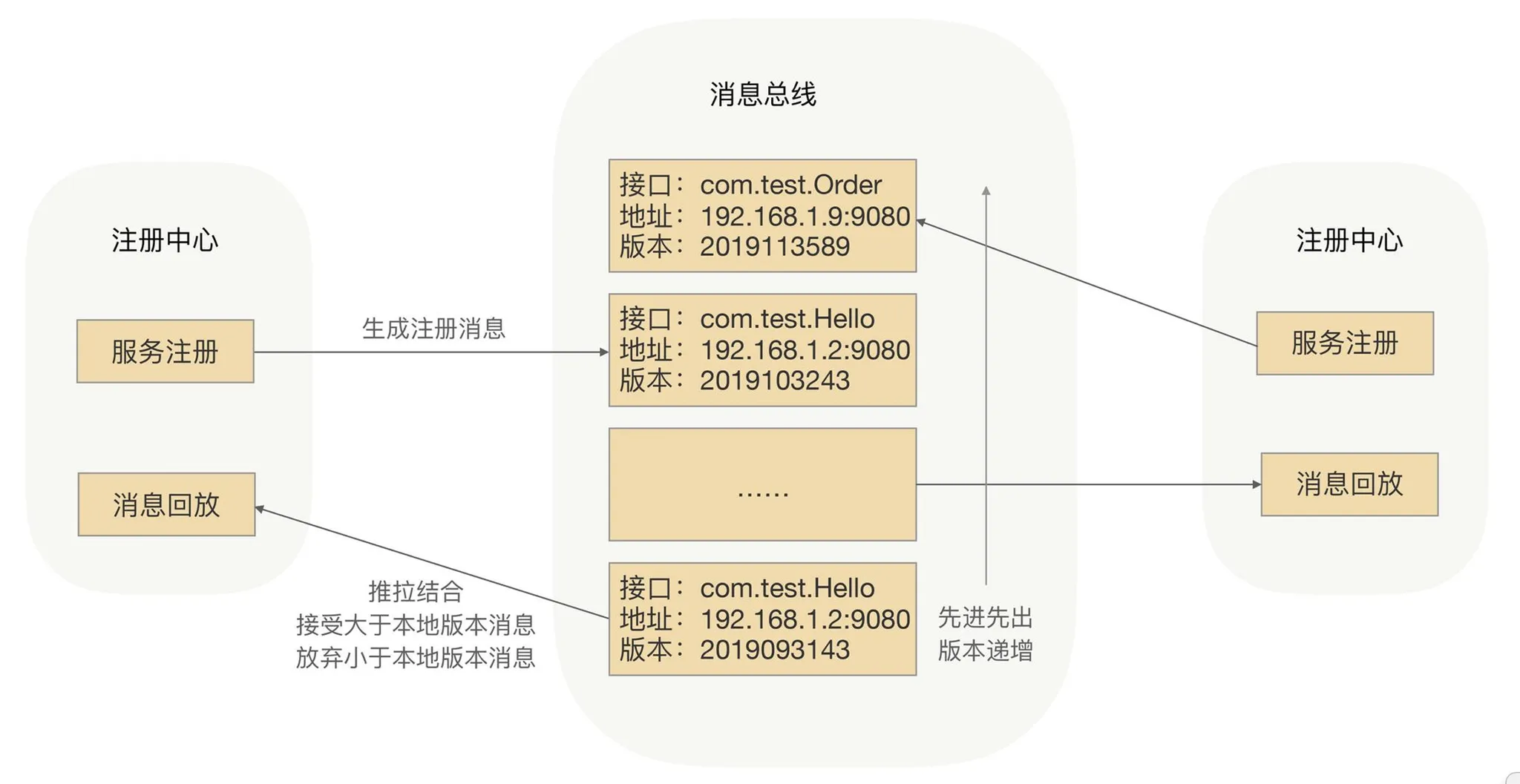
Eventually consistent registry (message bus)
Callers can tolerate learning about new pods seconds later; brief zero-traffic windows are often acceptable. Trading CP for AP improves registry scale and resilience.
Message-bus replication: each registry node holds a full in-memory cache; a registration event publishes on the bus; peers update and push new routes—eventual consistency across registry instances.
Afterword
Next steps: read gRPC and Kitex code, plus ByteDance cloud-native articles—but the deeper win is nailing fundamentals underneath any particular OSS project.